8. Mapping of clinical trial data to CDISC-SDTM: a practical example based on APPROACH and ABIRISK¶

8.1. Main Objectives¶
This recipe provides a general guide for mapping a clinical trial dataset to CDISC Study Data Tabulated Model (CDISC-SDTM) using practical examples from two Innovative Medicine Initiative projects, APPROACH and ABIRISK.
The recipe will cover the following elements:
Provide a general overview of the challenges of mapping a non-conforming data dictionary to CDISC STDM standard and CDISC Vocabulary.
Illustrate the mapping process using the above projects.
Describe the Extract-Transform-Load (ETL) processes necessary to convert the data to CDISC-SDTM based on the mapped data dictionary.
8.3. Requirements¶
Technical requirements:
Knowledge of relational databases is an advantage
Fluency in a scripting language such as bash, Python or R
Knowledge requirement:
A thorough understanding of CDISC standards, in particular CDISC-SDTM, is essential
understanding of what a data dictionary is.
8.4. Table of Data Standards¶
Data Formats |
Terminologies |
Models |
|---|---|---|
8.5. General challenges of mapping to CDISC-SDTM¶
CDISC-SDTM is a standard model and framework for organising, annotating and formatting data from clinical trials 3. Regulatory agencies, such as the US FDA, require clinical trial results to be submitted in this format. While SDTM is a very complex framework with a high learning curve, its ubiquity in the field of clinical trials makes it a useful interoperability tool for comparing and combining datasets. The SDTM Implementation Guide (SDTMIG) provides expanded guidance on implementing SDTM for specific use cases or “domains” 1. A general introduction to the SDTMIG is available on the CDISC website 2.
Warning
Given the complexity of CDISC standards, any project team intending conversion of their datasets to SDTM at any point in the project life cycle should aim to align with the standard as early on in the process as possible.
Data dictionaries and data collection instruments should, where possible, be aligned to the relevant CDISC standards to facilitate data conversions later on. In particular, CDISC standards provide procedures and guidelines for encoding project-specific data that might not fit into the existing domains.
Note
Commercial solutions are available to address all of these use cases but these are outside the scope of this recipe.
We will focus on outlining how to perform the mapping process manually, without bespoke tooling.
8.6. Step-by-step process¶
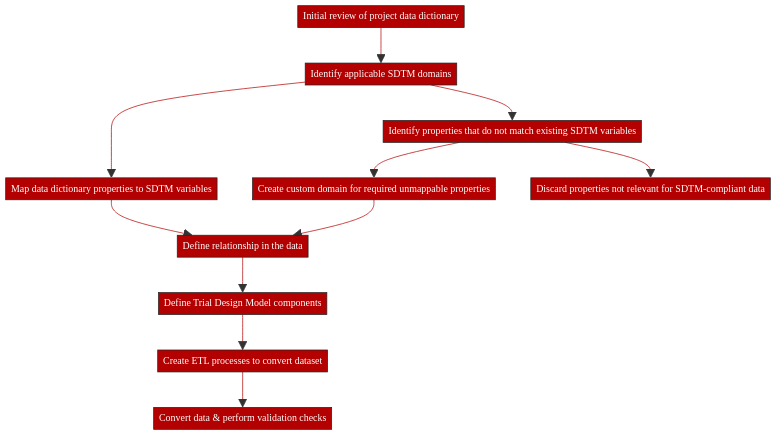
8.6.1. Initial review of the data dictionary & identification of relevant domains¶
Before any mapping can take place, it is essential to gain a good understanding of the project’s data dictionary, i.e. its list of variables, their types, definitions and domains.
A good data dictionary will already split properties into domains, for example: by data collection instrument or other data source.
Guidance for creating a data dictionary is available elsewhere in this Cookbook.
This step may also include reviewing actual data to refine contexts.
Once a good understanding of the data dictionary has been gained, the main domains from the SDTMIG that apply to this data need to be identified. Common domains that will occur in most clinical trial datasets include Demographics (DM), Medical History (MH), Laboratory Test Results (LB), Adverse Events (AE) and Vital Signs (VS).
The ABIRISK data dictionary already used a similar setup to CDISC-SDTM, which made this step relatively straight-forward.
The APPROACH data dictionary on the other hand used categories that, while providing a clear structure to the data, did not align directly with SDTMIG domains. This made the identification of appropriate domains more difficult and the initial list had to be revised several times during the variable mapping process, when variables were identified that didn’t fit within the primary domain matched to a data dictionary category.
8.6.2. Assignment of properties to domains and mapping to SDTMIG variables¶
Mapping of data dictionary properties to SDTMIG variables falls into several categories:
Direct match - a property from the data dictionary directly matches a variable in the SDTMIG.
Combination - two or more properties from the data dictionary need be combined into a single SDTM variable. As an example, sample collection times in the APPROACH dataset were recorded as separate variables for year, month, day, hour and minute. In SDTM, these were combined into LB.LBDTC.
Splitting - a property from the dataset needs to be split into component parts. This is commonly the case if values and units were captured together in the same field.
Derivation - some values might be derived from another value, for example using a logical decision tree “if A=x, then value=y” or transformed, e.g. converting a laboratory result reported in non-standard units into standard units.
Fixed value - an implicit field in the original dataset may correspond to a fixed value for an SDTMIG variable. In the APPROACH dataset, the demographics property “Age” has the unit “years” implied in the property description as the inclusion criteria for the trial specify adult subjects only. DM.AGEU is a required value so in this particular conversion, “YEARS” is set a fixed value.
One-to-many/many-to-one - In some cases, a single property might map to multiple SDTMIG variables, depending on the corresponding value in the dataset. Equally, multiple properties may map to the same SDTMIG variable.
Unmappable properties - some project-specific properties may not have an equivalent SDTMIG variable at all. If the property and its values are important for the interpretation of the dataset overall, this scenario may require the creation of a custom domain. Equally however, some properties may simply be out of scope of SDTM. The APPROACH data dictionary contains a number of such properties, including checks whether a given CRF, examination or questionnaire was completed or sample collected, and properties to identify the coder or analyst.
Auto-generated - some SDTM variables such as “STUDYID” or sequence ID (“-SEQ”) will likely not be encoded directly in the dataset and need to be autogenerated or autocompleted during the data transformation process.
8.6.3. Putting together an ETL template¶
For most of the scenarios listed above, with the exception of direct one-to-one matches, ETL scripts will need to be implemented in order to convert the data into an SDTM-compliant format. As the implementation of scripts was outside the scope of our mapping work, we instead implemented a template that could be used as a basis to generate the scripts. A copy of our template can be downloaded from this URL.
A recipe on ETL processes is available elswhere in this resource
8.6.4. Issues, pitfalls and caveats¶
One major issue that we encountered with both our mapping projects was trial/study data coverage gaps from the respective study data dictionaries. The SDTM includes an entire area called the “Trial Design Model”, which provides a structured way of representing all activities of a clinical trial, such as planned visits, treatment arms and inclusion and exclusion criteria. While this information is a key component of a completely SDTM-compliant dataset, it was not part of the data dictionary and was therefore not part of the mapping strategy. As a result, any ETL process covering the data alone would not have generated a fully SDTM-compliant dataset. Another area of the SDTMIG we did not include in our mappings was the representation of relationships in the data, such as those between different records for a given subject (RELREC domain). These relationships need to be factored into any ETL procedures but require additional documents, distinct from the Data Dictionary stricto-sensu and these relations cannot only be established working from a data dictionary, which only lists variables. In order to build those links, actual subject, specimen and visit information is needed. This information is specified in the SDTM syntax itself, which is outside the scope of this specific document.
8.7. Conclusion¶
We presented an overview of our approach to mapping project-specific data dictionaries to the CDISC-SDTMIG with a view to transforming the corresponding datasets to be SDTM-compliant.
The CDISC-SDTM standard supports the interoperability between datasets due to its high level of standardisation, detailed modelling and widespread use.
The high level of detailed knowledge of the standard required to successfully convert a dataset to SDTM presents a significant hurdle
8.8. References¶
References
- 1
Version 2.0 of the study data tabulation model (sdtm). 2021. URL: https://www.cdisc.org/standards/foundational/sdtm/sdtm-v2-0.
- 2
Version 3.4 of the study data tabulation model implementation guide (sdtmig): human clinical trials is intended to guide the organization, structure, and format of standard clinical trial tabulation datasets may be used for various purposes, including publication, warehousing, meta-analyses, and regulatory submission. it should be used in close concert with sdtm v2.0. 2021. URL: https://www.cdisc.org/standards/foundational/sdtmig/sdtmig-v3-4.
- 3
Wayne R Kubick, Stephen Ruberg, and Edward Helton. Toward a comprehensive cdisc submission data standard. Drug information journal, 41(3):373–382, 2007.
8.9. Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
University of Luxembourg |
|
Writing - Original Draft |
|||
University of Oxford |
|
Writing - Review & Editing |