FAIR and the notion of metadata¶

Main Objectives¶
The main purpose of this recipe is:
To introduce the notion of metadata and detail why it matters in the context of FAIR. This recipe aims to provide insights into the different types of metadata, why they differ, and how they relate to each other. We also introduce semantics elements, such as controlled vocabularies, to make metadata machine actionable.
Introduction¶
Upon reading the FAIR principles, one can’t help but notice that everything rests on the availability of machine readable metadata. For a number of newcomers to FAIR or Data Management for that matter, the first hurdle is to grasp the notion of ‘metadata’. Below are a number of commonly found definitions of metadata:
The recursive definition “data about the data”, which provides the idea that to understand data, you need extra data describing it 4.
The formal definition “set of agreed-upon descriptors to denote an entity”, which indicates that a social contract is needed to ensure we all mean the same thing when adding a descriptor.
The poetic definition “a love note to the future about data”, which conveys the notion that providing descriptors about data is an altruistic and caring action.
The fractal definition “your metadata is my data”, which conveys the notion that
quantity has a quality all of its ownwhen it comes to metadata, and by accumulating enough metadata, however small, statistical handling may reveal patterns and provide insights. This in fact can have unforeseen and possibly untoward consequences, such as loss of privacy and risks of reidentification of supposedly anonymized data.
The definitions above hints that metadata is indeed important and above all pervasive in any modern society which relies on information technology.
In the following sections, we will delve further into the possibly controversial typology of metadata 5.
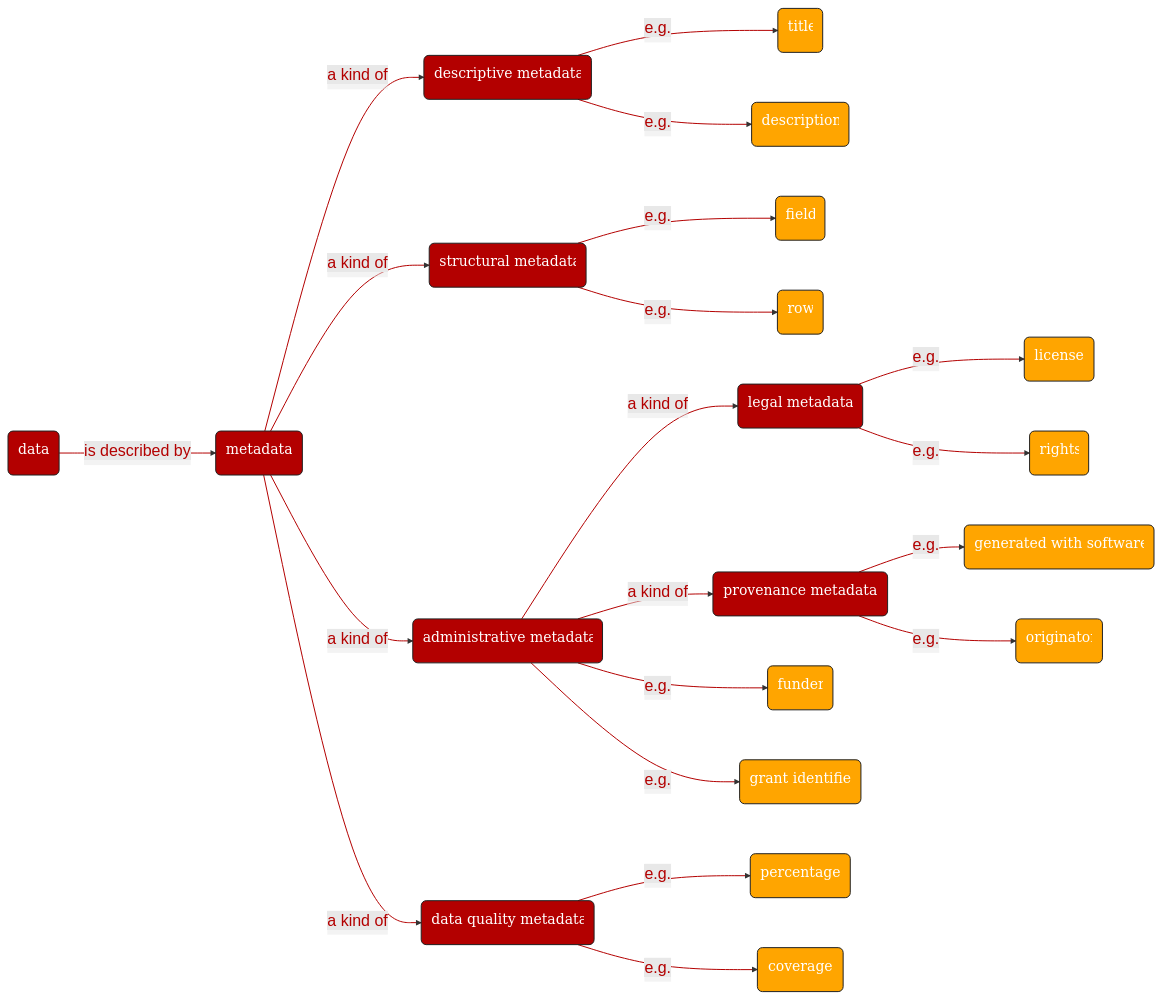
Different shades of metadata¶
In this section, we will build on the illustration presented above, provide more details, and frame the context of each of these definitions. Remember that for each of these definitions, we are actually talking about tags used to provide information about an entity, be it a physical object (e.g. a chair in your favourite furniture supplier) or a digital object (e.g. a file on a server).
1. Descriptive metadata¶
This is the fundamental of metadata, things should at least be described by a label, name, which is probably the simplest form of metadata: a small string denoting a thing.
Depending on the domain of knowledge, descriptive metadata complexity can increase.
Taking an example, let’s consider the domain of a bibliographic record and look at a BibTex 2 record:
@Article{Alter2020DATS,
Author="Alter, G. and Gonzalez-Beltran, A. and Ohno-Machado, L. and Rocca-Serra, P. ",
Title="{{T}he {D}ata {T}ags {S}uite ({D}{A}{T}{S}) model for discovering data access and use requirements}",
Journal="Gigascience",
Year="2020",
Volume="9",
Number="2",
Month="02"
}
In this object, seven metadata elements are provided, each of them meant to receive a specific category of information about a journal article. Each key in this JSON object corresponds to a metadata element the definition of which can be found in the BiBTex specification2.
2. Structural metadata¶
Structural metadata concerns itself with providing descriptors allowing agents to understand how data is organised. This type of metadata could provide information about the layout of a table, the relations between elements, and their types. Here are two historically important models:
-
OAI-PMH stands for the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) and is a low-barrier mechanism for repository interoperability.
-
The Portland Common Data Model aims to underlie a wide range of repositories and data asset management applications.
3. Administrative metadata¶
Administrative metadata covers things like record identifiers and can also include specialization such as:
3.1 Provenance metadata¶
This subtype of metadata is mainly concerned with capturing information about the agents and processes which produced the entity. So processes such as creation, modification, and conversion should be described, as well as the dates on which these have been executed and by whom. Versioning information also falls into this category of metadata information 1. This used to be known as “Audit Trail” information as it allows understanding of how information was generated and therefore provides tokens of trust and evidence which can be used to establish validity, reliability, and trustworthiness of data.
3.2 Legal metadata¶
This subtype of metadata concerns itself with providing tags to allow information about the condition of use of the data, copyright information, patent coverage, and likewise topic. It is essentially a piece of information to know about a dataset to decide if data use is allowed or not, as the implication of failing to comply with the terms of use can be far-reaching.
4. Quality metadata¶
This is possibly a more recent layer adding to the set of metadata. It provides specific elements to define indicators providing insights into the quality of a dataset or piece of information. It can range from quantitative metrics such as the variance or standard error of a variable or more qualitative aspects such as a discrete ranking 3.
Note
This typology can easily be criticised as the boundaries between different domains can be something blurred by underlying semantic models and granularity levels, so we advise the reader to be mindful of this. Volumes have been written on the topics and this is an area in constant evolution and where shape shifting happens.
Semantic frameworks for metadata¶
We have given an overview of the basic definitions of what metadata is and its various possible flavours. This raises an unanswered key question: How does it work in real life? For this, we need to look at some technical details and since we are dealing with things FAIR, we inevitably slide back into the notion of Linked Data and Resource Description Framework(RDF). This essentially means that we can not talk about machine actionable metadata (referred to in some quarters as ‘active metadata’) without talking about semantics and controlled terminologies on the one hand, and on the other hand about syntax and serialization format. This is simply because for computational methods to work, there need to be agreements, social-contracts, and protocols in place to define things to enable interoperability. As with all human things, there will be redundant, overlapping, competing efforts vying for a domain of knowledge. Semantic models for metadata do not escape this.
Conclusion¶
In this recipe, we introduced the concept of metadata and presented a possible typology for it. We also showed the close relation between metadata and semantic models used to represent information as well as how, with the reliance on the Resource Description Framework, the boundary with syntax and semantics somehow becomes more fuzzy. We therefore encourage readers to delve into these other sections of the FAIR Cookbook.
References¶
References
- 1
Casrai provenance metadata definition. URL: https://casrai.org/term/provenance-metadata/.
- 2(1,2)
Bibtex specifications. URL: http://www.bibtex.org/Format/.
- 3
Data europa. URL: https://data.europa.eu/mqa/?locale=en.
- 4
Metadata definition in wikipedia. URL: https://en.wikipedia.org/wiki/Metadata.
- 5
Jenn Riley. Understanding metadata. 2017. URL: https://groups.niso.org/apps/group_public/download.php/17446/Understanding%20Metadata.pdf.
Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
University of Oxford |
|
Writing - Original Draft, Editing, Conceptualization |
|||
Imperial College London |
|
Writing - Reviewing |
|||
EMBL-EBI |
|
Reviewing |