A framework for FAIRification processes¶

Main Objectives¶
This recipe provides a general introduction to the FAIRification Framework developed by FAIRplus.
The recipe will cover the following elements:
The components of the framework
Some practical considerations for applying the framework
This recipe will not provide instructions on how to practically implement the framework as this is covered elsewhere in this Cookbook.
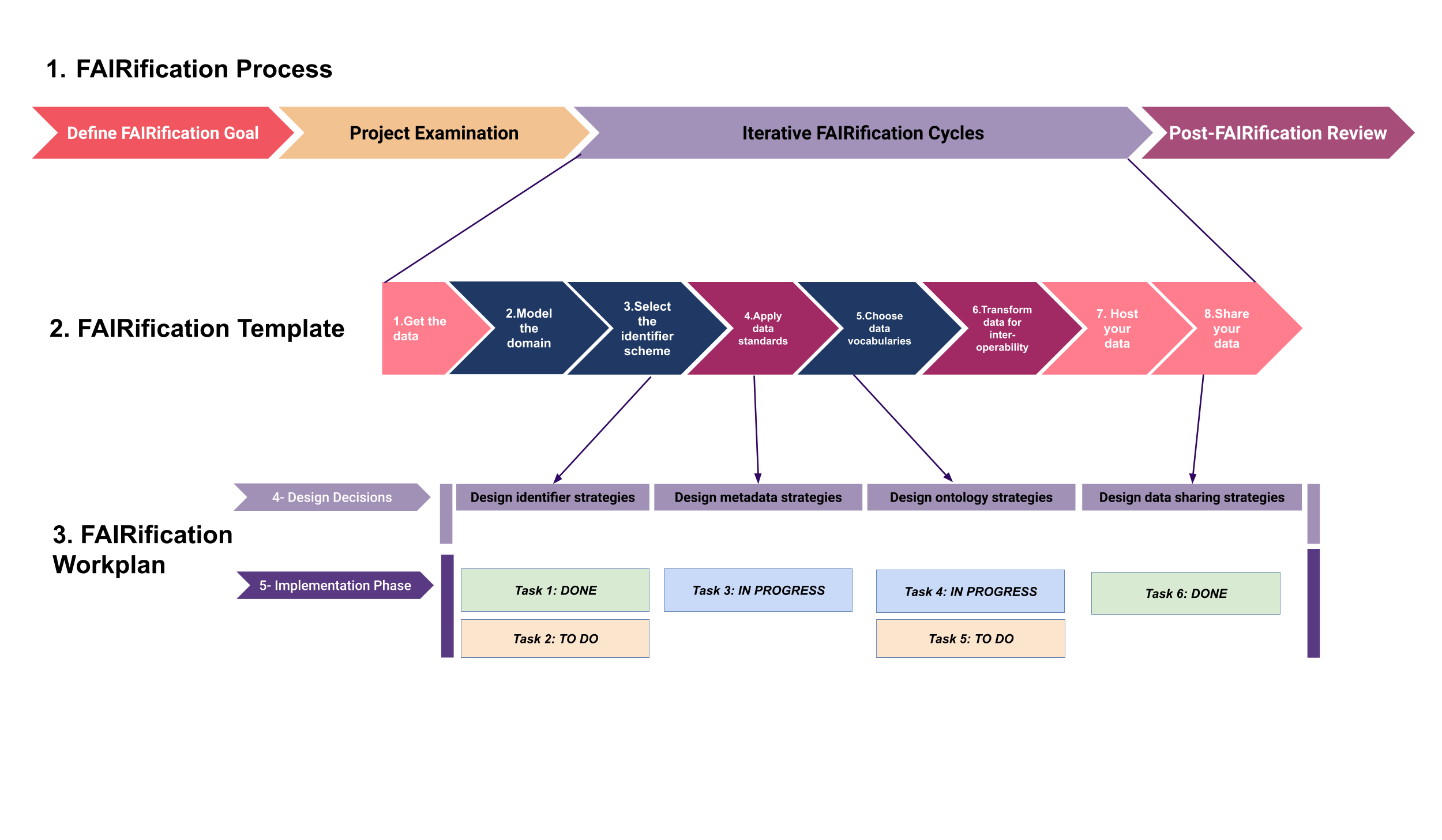
The FAIRification Framework¶
The FAIRplus FAIRification Framework was developed to address the significant demand for hands-on, practical advice on how to translate general and high-level FAIR principles into actionable, “tried and tested” processes. The framework was developed in an iterative fashion by a multi-disciplinary team of research scientists, data managers and software engineers from both academia and the pharmaceutical industry, and tested on a range of IMI partner projects.
The framework consists of 3 components:
a reusable FAIRification Process, which outlines the main phases of a FAIRification activity
a FAIRification Template, which breaks down key elements of the process into a series of steps to follow when undertaking a FAIR transformation
a FAIRification Workplan layout, which provides a structure for organising FAIR implementation work tailored to the needs of a specific project.
The FAIRification Process¶
The FAIRification process can be divided into four phases:
FAIRification goal definition
Requirement examination
Design and Implementation
Review
Note
Each of these phases are sequential dependent on each other and involve two to three groups working on them:
The first group is the data or project owner who plays the major role in definition of goals and reviewing the impact of the goals.
The second group involves the technicians who specialize in processing and analyzing the data to work towards the goal. They might be a subset of the data owner group, but a clear distinct between these groups should be made to delegate responsibilities and to attain results efficiently.
The third group is assessment group who are responsible for checking the alignment of the task done by the technician team and the goals set by the FAIRification team. The individuals involved in this team are not part of discussions between the data owners and technicians and hence act as peer-reviewers.
In the following sections, we will discuss in depth the work involved in the individual phases of the FAIRIfication pipeline.
Phase 1: define FAIRification goals¶
This phase involves the identification of outcomes and planning of goals that data or project owner would want to achieve upon FAIRification of the data. These goals are either centric to one aspect of FAIR, for example deposition of data to Zenodo to increase its findability, or they could cover multiple aspects of FAIR, such as use of consistent terminologies and controlled vocabularies to represent the data (interoperability aspect) along with deposition of data in relevant repositories (findability aspect).
Sometimes, the data/project owner may be at a loss when tasked with spelling out a clear FAIRification goal. In that case, tools such as the Dataset Maturity (DSM) model can assist in identification of goals. Check out the DSM recipe for more details on how the tool is able to accomplish it.
Phase 2: examine requirements¶
Upon identification of the goal by the data owners, a discussion with the technical team is done. The technical team then start with collection of the data to ensure that they have access to the data that needs to be FAIRified. If the technical team is external, certain legal aspects need to be placed for efficient transition of data between the data owners and technicians (for example a DPIA may be needed, see this recipe (dpia.md) for more details).
Following this, the technical team identifies tools and expertise required for the implementation of the work and start cataloging this material. Lastly, the team collectively decides on the individuals that would be assigned the FAIRification task.
At the end of this phase, an “action” team (subset of the technical team whose goal is to perform the FAIRification tasks) is in place along with a catalog of tools and resources that would be used for achieving this goal.
Phase 3: assess, design, implement, repeat¶
Following the selection of the “action” team, an iterative cycle of assessment, design, and implementation in put in place.
Assessment : Prior to starting the work, the assessment of goals is done to ensure that individuals in the action team are updated and clear with the FAIRification goals formulated by the data owners. This assessment is carried out by review team which could be an independent team or certain individuals from the technical team who are not involved in the action team. The assessment involves a binary decision of “GO” or “NO GO” based on the FAIRification goals and the catalog provided. At this stage, the reviews can also provide suggestion based on their experiences on the resources, tool, or goals.
Design : Once the team receives a “GO” decision from the review team, the action team now starts by enlisting the steps that need to be done performed to achieve the goal. For each task, the resources, an estimate time duration, as well as the responsible person is selected.
Implementation : Once the tasks have been selected and assigned, the actual work begins. To ensure that the action team is working smoothly, weekly or bi-weekly meetings is recommended so that the team is aware of the progress.
Once the implementation of task listed in the design phase are done, the action team assess the work done and checks the aligned with the FAIRification goal. In case more tasks are needed to achieve the goal, a second round of the assess-review-implement cycle takes place as described above with the starting point as the FAIRification goals, the completed tasks and the proposed task
This phase is usually run in short sprints of 3-month.
Phase 4: review against the goals¶
At this phase, the FAIRification work has been completed by the team. The technical team and the data owners now come together to assess the output of FAIRification. At this point, the technical team packages all the work done and hands it over to the data owners. Decisions on the key learning as well as future aspects of the work take place. Finally, to ensure that the work done is sustainable, the deposition of workflows and the information on steps is deposited on online catalogs and recipe books such as teh Cookbook, RDMKit, IMI Data Catalog to name a few.
The FAIRification Template¶
The FAIRification template provide an outline of possible FAIRification aspects a dataset could be considered for.
Note
This template was formulated based on retrospective and prospective experiences of FAIRification of datasets within IMI FAIRplus and does not represent the exhaustive list of all potential FAIRification aspects.
The template provides an overview on the data from 3 perspectives: Contents related, Representation and format, and the hosting environment capabilities. Covering these three aspects, 8 steps are required for the implementation of the FAIRification template as shown in Figure 3. We discuss each of the steps below in detail:
FAIRification template
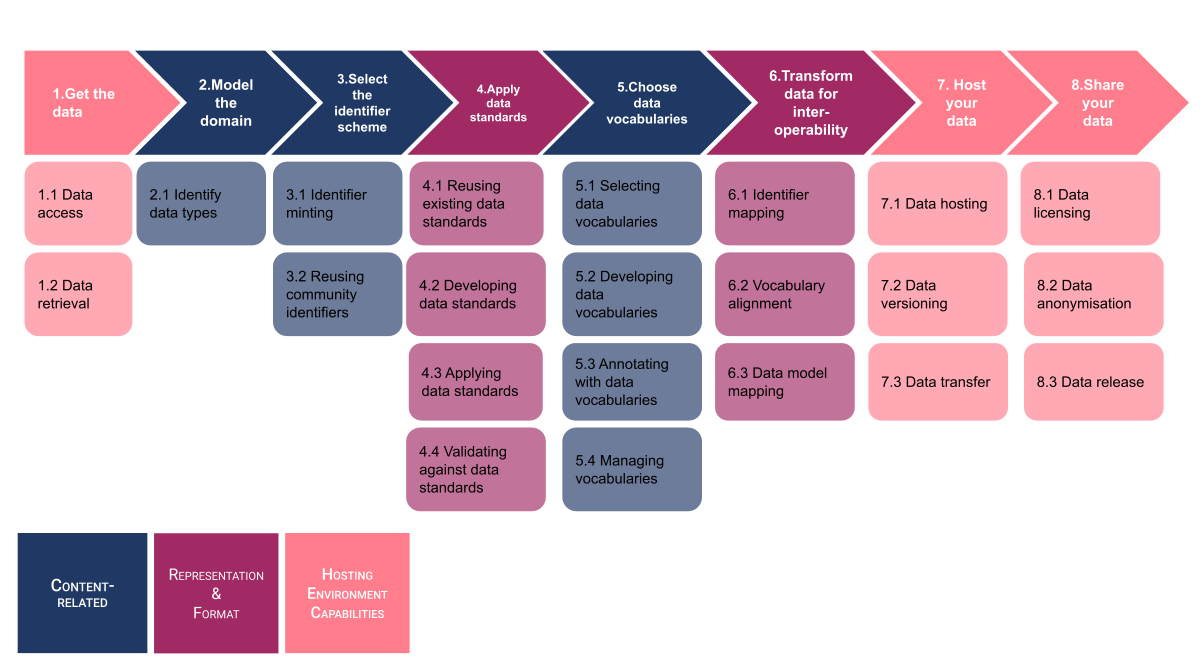
Fig. 3 FAIRification template¶
Step 1: Get the data: This step involves getting access to the underlying dataset via a restricted or open access API and capturing information on how to query the data via the API.
Step 2: Model the domain: Here, the data types involved in the dataset are identified. Also, the community or domain standards for representation of the data are also captured to align the FAIRification work, if any, along those lines.
Step 3: Select the identifier scheme: Here, the establishment of an identifier for identification of the dataset is done. This could be achieved by generation of new identifiers or reusing of existing ones.
Step 4: Apply data standards: At this step, data standard validation and identification is done to ensure that the representation of the data is in community or domain specified formats for interoperability purposes.
Step 5: Choose data vocabularies: At this step, you would look in depth about the data content and harmonize it with ontologies either pre-existing or formulate an application ontology for your use case.
Step 6: Transform data for interoperability: Not only would you represent the data in one ontology but also link or map to corresponding ontologies such that the data is interoperable with multiple vocabularies and terminologies rather than just one.
Step 7: Host your data: Once the dataset is ready, hosting and search engine optimization inputs for the dataset need to be in place. Alongside hosting, data versioning and data formats need to also be considered.
Step 8: Share your data: Now that the dataset is FAIRified, one can share this data to the community with licensing. In case of dealing with sensitive data, data anonymization considerations should be placed prior to sharing.
The FAIRification Workplan¶
The FAIRification Workplan is a specific design and implementation plan generated for a specific project based on the goals set in phase 1 and requirements identified in phase 2 of the Process. Relevant elements from the FAIRification Template are selected and broken down into concrete tasks. These tasks are then completed within the agreed cycle time frame as per the FAIRification Process.
The diagram below shows the bespoke FAIRification Workplan for the CARE project. The Workplan follows the general outline of the FAIRification Process, with the goals listed in section 1 (red), the outcomes of the project examination on section 2 (orange) and the pre-FAIRification assessment outcomes in section 3. It can also be beneficial to explicitly list the indicators targeted for improvement in this section in order to keep this information easily accessible in one place.
The key parts of the workplan are section 4 (Design Decisions) and 5 (Implementation). Section 4 lists the specific steps from the FAIRification Template that will be addressed in this FAIRification cycle (dark purple) and refines them into more concrete steps relevant for this context (light purple).
In section 5, these concrete steps are broken down into clear implementable tasks, which are recorded in colour coded boxes to track progress. If a Cookbook recipe already exists to address a task, this can be linked here.
Following a FAIRification cycle, the results of the post-FAIRification assessment are recorded in section 6.
If more than one FAIRification cycle is performed, a new version of the Workplan should be produced for each cycle, in particular if there are changes in sections 4 and 5.
FAIRification Workplan CARE project
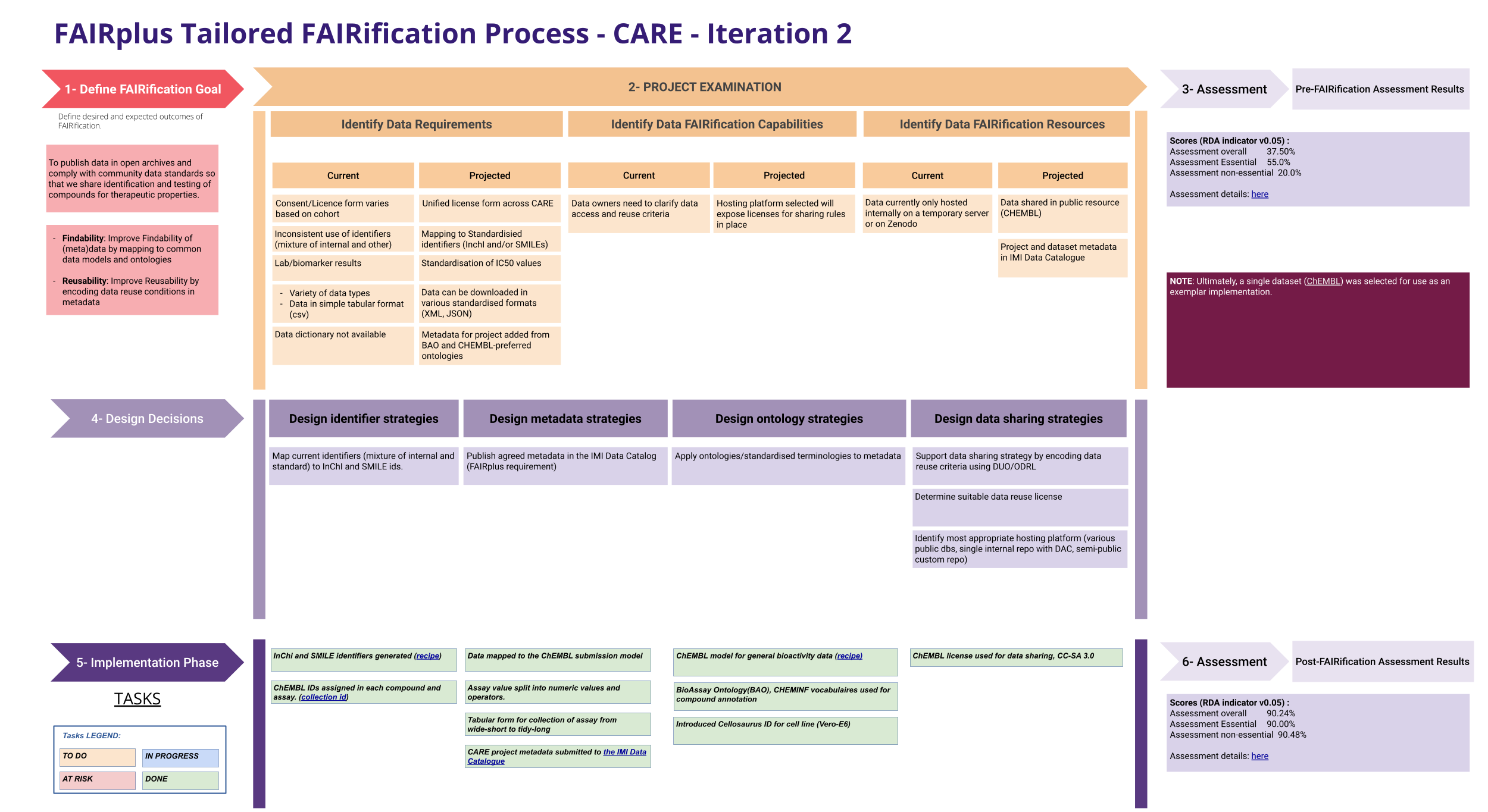
Fig. 4 FAIRification Workplan CARE project¶
Practical considerations¶
While this recipe does not deal in detail with how to implement the FAIRification framework, as this is covered elsewhere, it is worth highlighting a few important practical considerations:
The importance of good goal setting. Throughout the development of the framework, we tested iterative versions of the framework on a range of use cases brought to us by other IMI projects. One of the standout lessons from these collaborations was that good FAIRification goals lead to good FAIRification goals. The characteristics of a good FAIRification goals are:
Actionability: goals need to be translatable into concrete tasks. A goal that is too vague can be difficult to implement as it is unclear what steps are involved in its completion.
Defined scope: a good goal has a clearly defined scope or endpoint. Without this, work on an open-ended goal is likely going to carry on indefinitely with diminishing benefits.
Scientific value: FAIRification work comes at a cost so a good FAIRification goal needs to explicitly state why the work will increase the data’s scientific value. Investing a great deal of effort to FAIRify a single-use internal dataset that is not intended to ever be shared or reused would not constitute a prudent investment of resources.
Multi-disciplinary task teams. FAIR considerations range across a range of skill levels, from highly technical work such as the practicals of data access control or ontology maintenance to data management aspects such as the creation of data dictionaries to project-level governance issues like data licensing and reuse conditions. A successful FAIRification process will therefore involve the assembly of a multi-discplinary task team of data managers, software developers, research scientists and project managers, to name just a few. The exact composition of a task team depends on the nature of the FAIRification tasks and may change over the course of the FAIRification process, with different skills required in the goal setting and project examiniation phases than during task implementations.
Flexibility of the framework with regards to specific FAIR approaches or implementations. The FAIRification Framework described here is agnostic of any specific FAIR implementation such as different FAIR assessment methodologies. During the development of the framework, we trialed a range of methodologies including RDA, FAIRsFAIR and FAIR Dataset Maturity (DSM) indicators to assess FAIRification as well as a range of tools to support the definition of FAIRification goals and their translation into a workplan.
Conclusion¶
The key take-homes of this recipe are:
Tailor the generic FAIRification process to individual needs. There is no single right way to “do FAIR” and every project will have a distinct set of needs and requirements. Customising the relevant template elements allows the building of a coherent workplan that optimally supports a project’s needs.
Carefully define FAIRification goals, focusing on incrementally achievable targets. Focus on achieving elements of FAIRness that matter most to the needs of the project to reach a balanced “FAIR enough” status.
Assemble a multi-disciplinary team. A successful FAIRification process starts with bringing together diverse teams that include the data owners as well professionals who can tackle the legal, curatorial and technical infrastructure aspects.
References:¶
References
Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
University of Luxembourg |
|
Writing - Original Draft |
|||
Fraunhofer Institute |
Writing - Original Draft |