7. Using OpenRefine and Karma for FAIRification¶

7.1. Introduction¶
FAIRification is a multi-step process that can be performed via different workflows and at different levels of completeness.
Here, we focus on “fully FAIRifying” data “a posteriori”.
That is to express the content of the information (entities, attributes, relations, values) via ontologies (when applicable) and, in particular, through URIs.
The processed information results in an RDF/Linked Data graph, that can be seen as a specific implementation of a Knowledge Graph (KG in short). By virtue of using coherent URIs, different datasets are automatically (logically) merged when represented as a graph.
For simplicity, we focus here on “input” data that is represented as tables.
Two fundamental steps are needed to perform such transformation:
Reconcile entities.
That is assigning the same URIs to the same entities, even when these are referred to by different names.
Note
In practice, we could have different but related URIs. It remains that in this step, we should go beyond names (labels) and use coherent identifiers to point to the entities names refer to.
Map the structure of the data to an ontology.
This is akin to reconciling properties (referred by a name, e.g.: a column name) to relations, attributes, and classes in an ontology. Except for simple cases, such mappings go beyond simple names to URI relations and generally include small graph patterns.
Note
As for many data cleansing exercises, we may need extra steps that are not specific to the transformation to a KG, but often necessary. For instance, split an “address” in “Country”, “Street”, “City”).
We mentioned that we assume here that source data is represented as one or more CSV files. There are some considerations to be taken if files are in multiple tables (as extra attention can be paid to “linking keys”) or in complex data structures such as XML, JSON etc. Tabular data covers a prominent use case for data FAIRification and is a building block for complex conversions.
We focus here on data (rather than metadata), though the distinction between the two vanishes when information is expressed as a KG.
7.1.1. Reconciliation¶
An essential element of FAIRification is the ability to identify entities via ontology terms. In general by “reconciliation”, we mean the capability to identify an entity (via an ID from a knowledge base) given one or more references and eventually additional information.
7.1.1.1. Ingredients for reconciliation¶
We generally need:
A source of knowledge to reconcile to. This could be expressed as a knowledge graph (KG), see Public knowledge graph resources for life sciences.
A system implementing some logic to reconcile a dataset to such a knowledge base, that is ideally automated. Such a system would receive as input at least a reference (e.g.: name) to the entity, but could also receive additional attributes or context for the name.
Ideally a system to perform Quality Assessment (QA) and curation (especially if point 2 is automated).
7.1.2. Reconciliation with OpenRefine¶
OpenRefine is a Desktop tool to cleanse data that proposes a simple workflow for data reconciliation 1. In particular, users can load data as a table, and for a column, they can call a “reconciliation service”: this will suggest what are the types of entity in a column (e.g.: drugs, treatments) and the user can then ask to reconcile to entities of one or more of these types. OpenRefine will then present candidates URIs, together with a preview (when URIs are resolvable) and confidence so that the user can control the proper reconciliation.
Fig. 7.3 OpenRefine¶
OpenRefine: https://docs.openrefine.org/manual/reconciling
In practice, OpenRefine presents an interface for QA and curation on a set of reconciliation proposals. Such proposals are provided by reconciliation services: systems that implement a set of OpenRefine compatible APIs.
There are publicly available reconciliation services, but it is also possible to implement ad-hoc services (e.g.: on top of an MDM system). Via a plugin called grefine-rdf-extension https://github.com/fadmaa/grefine-rdf-extension
It is also possible to use a generic triple-store as a reconciliation service.
Note
In that case, the triple-store should contain a list of entities, with labels in one or more languages and the corresponding classes. The triple-store should also be accessible on the network where OpenRefine is running. (no authorisation is possible, except via extensions).
7.1.3. Reconciliation toward public knowledge-bases¶
7.1.3.1. Reconciliation toward wikidata¶
One of the best developed systems supporting reconciliation APIs is Wikidata (https://wikidata.reconci.link). By specifying the URI: https://wikidata.reconci.link/en/api as a reconciliation service, OpenRefine will help users to normalise entity references to Wikidata URIs.
Fig. 7.4 Wikidata Reconcile for OpenRefine¶
Warning
The drawback of using Wikidata is obviously that not all entities exist in Wikidata, in particular entities which may be not public, as in a company setting.
7.1.3.2. Other public reconciliation services¶
Several public resources provide support for OpenRefine reconciliation services.
Note
in OpenRefine, users can use various reconciliation services over the same dataset. The reconciliation is column specific.
7.1.4. Reconciliation toward private knowledge bases¶
OpenRefine can also be used for internal data (e.g.: MDM systems), by providing “internal” reconciliation services.
This can be done in several ways:
7.1.4.1. Wikidata as a local instance¶
One way of providing reconciliation services for OpenRefine on internal data is to leverage the Wikibase system (the system at the basis of Wikidata).
We could implement a local “empty” version of Wikidata, and populate it with internal data (represented using the Wikidata format).
Dedicated deployment scripts can help in installing and administering an empty Wikibase system. These scripts are available from https://github.com/FAIRplus/WikiDraftWorks
Fig. 7.5 WikiDraftWorks¶
7.1.4.2. Reconciling toward a triplestore¶
When reference data and ontology exist in a triplestore, a simpler way to support OpenRefine is via its grefine RDF extension plugin. This allows to specify any triplestore as a reconciliation service, provided it contains suitable content (e.g.: instances with labels and their categorisation in classes). This extension graphical user interface (GUI) for exporting data of Google Refine projects in RDF format. The export is based on mapping the data to a template graph using the GUI.
The RDF transform extension now replaces ‘grefine’
Note
Note that this is not equivalent to the Wikidata services: as the plugin works over SPARQL, it has fewer capabilities in terms of ranking of results.
7.1.4.2.1. Authentication¶
One limitation of the above approach is that OpenRefine does not support authentication. Any services or triple stores it reconciles to need to be accessible on the same network where the OpenRefine client is working. In an enterprise setting, this is a serious limitation, as data is protected by access policies.
A possible workaround is an OpenRefine extension that implements authentication (tested with AllegroGraph based reconciliation services).
7.1.4.3. Implementing reconciliation APIs¶
Finally, it is possible to implement reconciliation APIs on top of proprietary systems (e.g.: MDM): https://reconciliation-api.github.io/specs/latest/
In this case, more complex reconciliation logic can be implemented. OpenRefine APIs could be one of the possible interfaces for more fundamental reconciliation services (e.g.: made available in R, Python,…).
7.2. PROs and CONs of reconciliation in OpenRefine¶
7.2.1. Limitations¶
7.2.1.1. Client tool¶
OpenRefine is a DeskTop tool. Though implemented as a web C/S system, it does not support concurrent users. Therefore, what can be done on OpenRefine is limited by the technical specification of the client, which is typically an edge device in modern enterprise environments.
One way to circumvent this limitation is to make OpenRefine accessible in a virtual desktop that can reside on a remote desktop. When doing so, it would be useful if data could be loaded from some shared central filesystem, as OpenRefine by default will consider the file system of the virtual desktop environment it is running on.
An extension of OpenRefine implements this kind of network access
https://github.com/FAIRplus/OpenRefine_local_file_extension
(to connect to a shared drive)
possibly extended by
https://github.com/FAIRplus/OpenRefine_Docker
(embed ways to tune configuration when starting OpenRefine in a server way)
7.2.1.2. Authentication¶
As previously mentioned, OpenRefine does not support access to restricted reconciliation services.
An extension providing such capability (tested on AllegroGraph) is available at:
7.2.1.3. Performance¶
Reconciliation in OpenRefine is not suitable for high data load, in that it is implemented via API calls and the performance is very limited. Recent development of OR maye have improved performance. A Lot depends also on the implementation of the reconciliation APIs (in terms of parallelism). It is advisable to use reconciliation functions for datasets in the hundreds rows range. Furthermore, there is limited value in using OpenRefine in ETL processes where its interactive capabilities are not used.
7.2.2. When to use OpenRefine¶
OpenRefine is a simple user oriented tool, useful for low curation loads where the aspects of reconciliation are prominent. It is particularly good as first tool to introduce reconciliation concepts in an organisation.
Note
OpenRefine can be used in more complex scenarios when its overall data cleansing capabilities are used. We focus here only on some FAIRification related capabilities.
7.2.2.1. Mapping the structure of data to an ontology {#mapping-the-structure-of-data-to-an-ontology}¶
The other essential step when transforming a dataset to a KG is mapping its structure to a graph. Let’s introduce this notion via a very simple example.
| Person | Father |
| Albert Einstein | Hermann Einstein |
After reconciliation, we could imagine this data to look like:
| Person | Father |
| http://www.wikidata.org/entity/Q937 | http://www.wikidata.org/entity/Q88665 |
[PUT CORRECT URIs ABOVE]
To express the above as a graph, we need to make the structure or this table explicit, referring to an ontology, example, for people and relations.
Tip
Wikidata uses 2 sets of uri
https://www.wikidata.org/wiki/Q937 (does not work in the wikidata sparql endpoint)
vs http://www.wikidata.org/entity/Q937
(should be used for the sparql: these uri redirect to the html link above)
Important point to bear in mind when using Wikidata.
Note that first we could map:
| Person => http://www.wikidata.org/entity/Q5 (Human, the type of the entity in the column) | Father =>
http://www.wikidata.org/entity/Q5 (Human, the type of the entity in the column) => http://www.wikidata.org/entity/P22 (father, the relation to the other entity) |
| http://www.wikidata.org/entity/Q937 | http://www.wikidata.org/entity/Q88665 |
Note that we need to have a way to express how “columns are linked together”. The full graph from the above example would look like [PSEUDO RDF, TO CORRECT]:
http://www.wikidata.org/entity/Q937 instanceOf http://www.wikidata.org/entity/Q5
http://www.wikidata.org/entity/Q937 rdfs:label “Albert Einstein”
http://www.wikidata.org/entity/Q88665 instanceOf http://www.wikidata.org/entity/Q5
http://www.wikidata.org/entity/Q88665 rdfs:label “Hermann Einstein”
http://www.wikidata.org/entity/Q5 http://www.wikidata.org/entity/P22 http://www.wikidata.org/entity/Q88665
Property: http://www.wikidata.org/entity/P18
Vs
https://www.wikidata.org/wiki/Property:P18
http://www.wikidata.org/prop/direct/P18
Warning
Check documentation about the wikidata model to understand the various identifier patterns and their meaning/effect
7.2.2.2. Mapping in OpenRefine¶
The RDF plugin in OpenRefine allows to map a table in OpenRefine to a graph pattern where the content of other columns can be added.
[BRIEF SCREENSHOT FROM THE WEB]
[ADD LINK TO TUTORIALS]
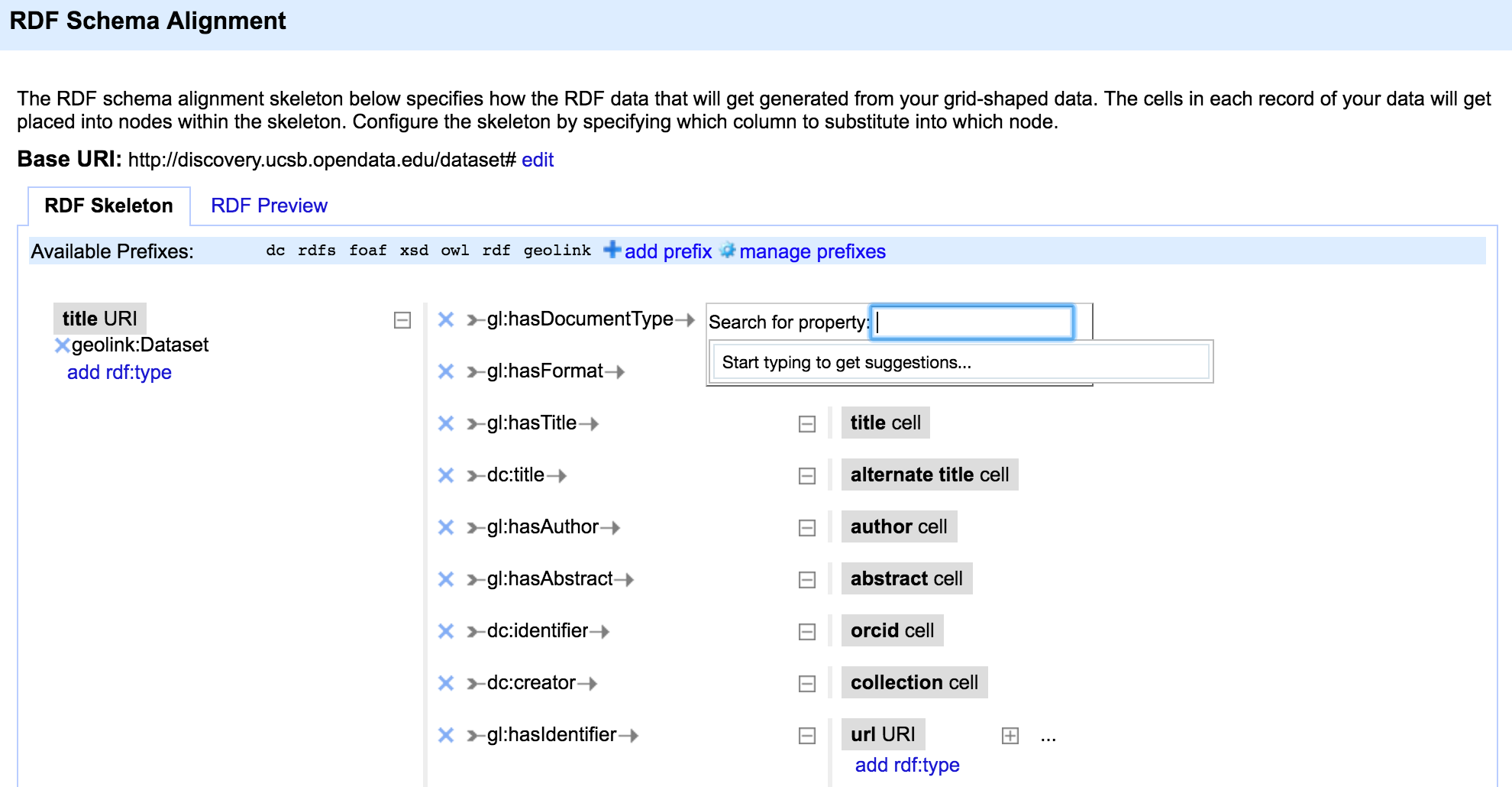
Fig. 7.6 RDF schema alignment in OpenRefine¶
The system assists the users in defining how the table should look like in RDF, fundamentally providing a template editor.
[MAYBE ADD RUN EXAMPLE FROM THE SIMPLE TABLE ABOVE HERE].
[TO REMEMBER/CHECK: does it make blank nodes? Where does auto-suggest fish from?]
7.2.2.3. Mapping in Karma¶
Karma (https://usc-isi-i2.github.io/karma/) is a Desktop tool specifically designed to map data to RDF. It covers different input formats (e.g.: JSON and hierarchical content). In terms of functionality, it is different from OpenRefine in some fundamental ways:
Use of ontologies. When mapping a dataset to RDF, one can create the required classes and properties URIs “while doing the mapping”. Karma requires the full ontology to map to to be present a-priori.
Mapping suggestions. Thanks to knowing the target ontology, Karma can learn from previous mappings and provide increasingly accurate suggestions.
User interface. Karma allows to paint the graph pattern over the table, while OpenRefine has a more crude text-based interface.
Data reconciliation. This is very limited in Karma (limited to three entity types only!).
Generic data transformation. Both tools can apply simple data transformations (e.g.: via javascript function).
However, OpenRefine is far more complete in these functionalities.Batch processing. Karma is an editor that saves a specification file that can then be invoked via the web interface but also via command line and eventually in a high performance spark environment. OpenRefine batch capabilities are very limited (In the latest version, OpenRefine is also implementing a spark architecture, albeit locally on the Desktop machine). Karma expresses mappings in the KARMA language, that is an extension of R2RML.
An example of a mapping session in Karma:
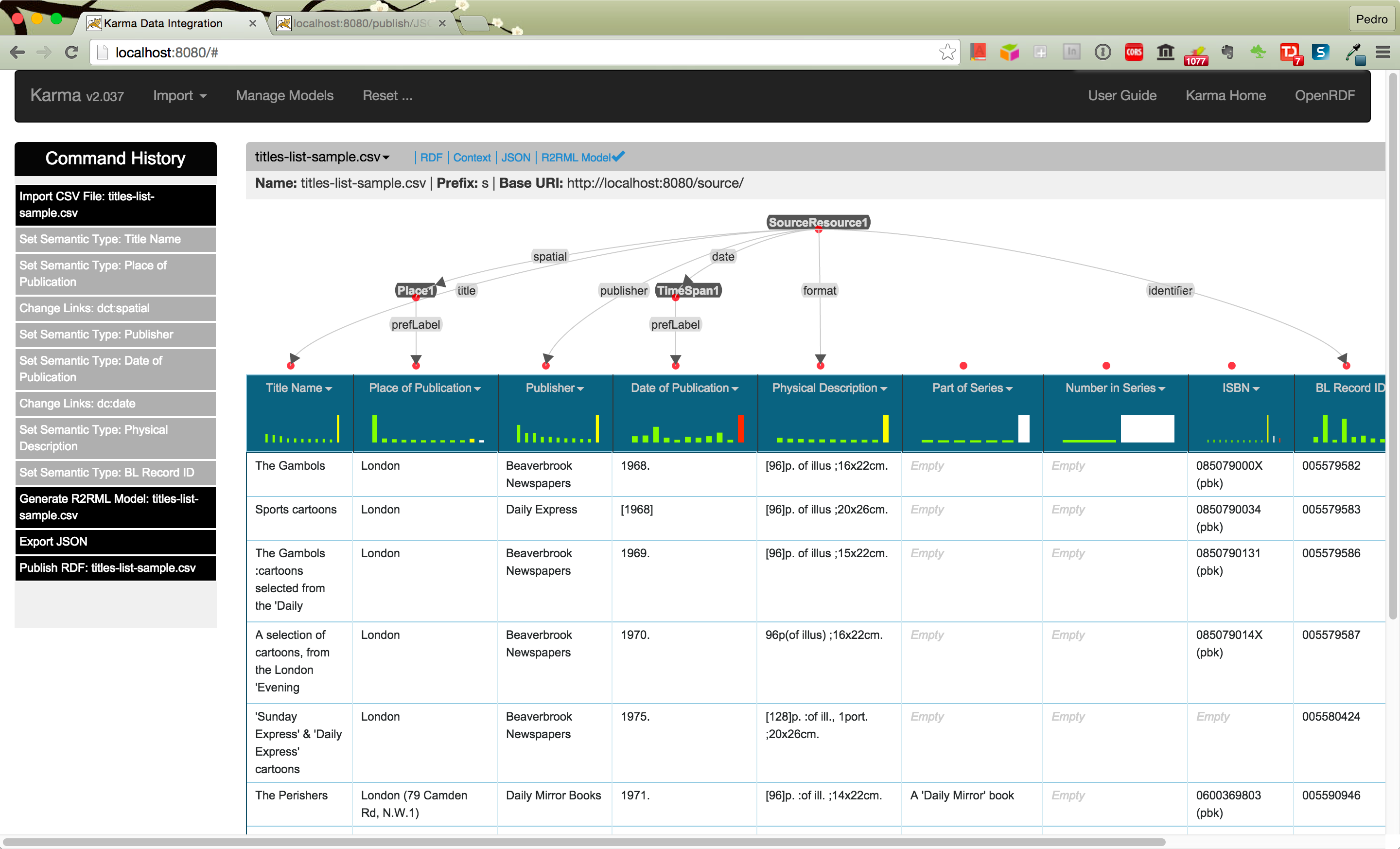
Fig. 7.7 RDF schema alignment in Karma¶
[https://github.com/szeke/karma-tcdl-tutorial/wiki]
[SHOULD HAVE A STEP BY STEP EXAMPLE WITH THE ABOVE SIMPLE TABLE]
7.2.2.4. R2RML¶
When source data exists in a relational structure, a mapping to a graph can be expressed via the standard language R2RML (https://www.w3.org/TR/r2rml/).
7.2.3. Notes on the FAIRification (as a KG) workflow¶
7.2.3.1. What comes first¶
Reconciliation and mapping to a graph are to a degree two independent steps. The Typical OpenRefine workflow would first do reconciliation and then mapping. In general, it makes sense to follow these steps in this order: when mapping to a graph, one could take specific actions depending on whether an identifier was found or not. And predictive approaches could be made more precise.
It is however possible to map data to a graph without performing any reconciliation step (in general the resulting graph will not be fully FAIR).
7.2.3.2. QA and staging¶
OpenRefine is an interactive tool and the user explicitly needs to select which “reconciliation proposal” to select among a few presented. In general automated reconciliation processes will provide suggestions with a confidence level. It is important to design systems where a QA can be put in place. One approach could be to have staging area where mappings are reviewed, and only approved ones can be merged in an overall KG.
7.2.4. Working on the graph¶
A useful set of tools for KG manipulation is the KGTK: https://kgtk.readthedocs.io/en/latest/
This provides Import/Export between different formats, operators (e.g.: as joins, sub-setting) and useful analytical functions.
[NOTE: NVS ENGAGED IN A PROJECT FOR KGTK EXTENSION]
7.2.5. Closed loop FAIRification [very draft, but we did have some architectures here]¶
We can use OpenRefine to FAIRify data using a KG as a source of “reference information” or ontologies.
At the same time we can export data via OpenRefine into a KG.
We therefore have a system that can be used to generate a KG that improves the performance of the system itself.
A particular aspect of (automated) FAIRification would then be to have systems able to automatically link data to an overall knowledge graph.
7.2.6. Exploring the graph¶
7.2.6.1. RelFinder¶
Once we have information as a KG, it is useful to have tools to explore it. One such simple tool is RelFinder ).
The tool can be pointed to a triplestore and allows discovering connections between two or more entities. Its capabilities are very limited, and it does not perform an exhaustive search, and being implemented in Flash, it is now obsolete. However, it is a useful tool to demonstrate why a KG is useful.
An implementation on a more modern technology stack is available at https://github.com/FAIRplus/RelFinderNG,
and many more tools and libraries exist to provide visual insights over KG https://graphdb.ontotext.com/documentation/free/devhub/custom-graph-views.html
7.3. Conclusion:¶
This content provides a basic overview of reconciliation tools for dealing with relative lightweight processes to convert tabular data to an RDF Linked Data graph. It complements content related to ETL to RDF. While a lot of material already exists about using OpenRefine for performing such tasks, the value added by the recipe rests on the setting up of a Wikibase instance to provide the reconciliation reference.
7.3.1. What to read next?¶
[Using OntoRefine to Transform Tabular Data into Linked Data](https://medium.com/wallscope/creating-linked-data-31c7dd479a9e
OntoRefine tutorial by OntoText
FAIRsharing records appearing in this recipe:
7.4. References¶
Reference
- 1
Antonin Delpeuch. A survey of openrefine reconciliation services. CoRR, 2019. URL: http://arxiv.org/abs/1906.08092, arXiv:1906.08092.
7.5. Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
Novartis AG |
Writing - Original Draft |
||||
University of Oxford |
|
Review & Editing |
|||
Fraunhofer Institute |
Review & Editing |