14. An inventory of tools for converting data to RDF¶

14.1. Main Objectives¶
The main purpose of this recipe is:
Present an inventory of a selection of popular tools for converting datasets in different formats (e.g. CSV, JSON, RDBMs, XML) to RDF, and to provide guidance for choosing the right tool.
14.2. Graphical Overview of the FAIRification Recipe Objectives¶
Figure Fig. 14.1 shows an example ETL workflow.
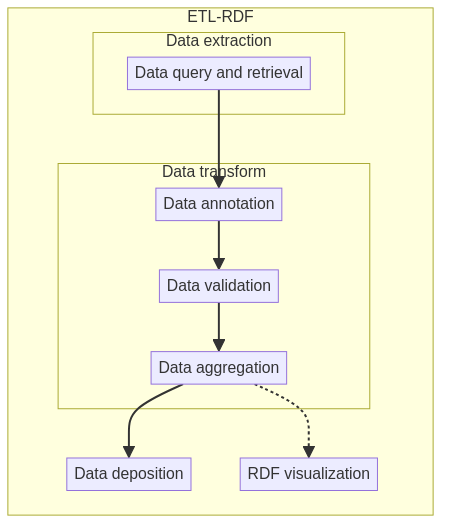
Fig. 14.1 Building an ontology with Robot tool.¶
14.3. Requirements¶
recipe dependency:
This recipe is an example of how to perform ETL with the RDF model. For tools on general ETL process. Please check recipe Extraction, transformation, and loading process
knowledge requirement:
basic understanding of: command line syntax, RDF, configuration using YAML
other:
plan/model of how to map your source entities/properties to classes/types/properties, and how to create resource URIs
14.4. Table of Data Standards¶
Data Formats |
Terminologies |
Models |
|---|---|---|
R2RML |
||
RML |
||
YARRRML |
||
YAML |
14.5. Introduction¶
Research data is produced in a range of different formats, such as spreadsheets, delimiter-separated files (CVS, TSV), or (relational) databases. To improve reusability of data and make them more FAIR, these data sets can be published in the de facto standard for reusable data, RDF.
There are many tools available to convert non-RDF data to RDF, a process also known as ‘triplification’ or ‘RDFizing’ of data. See for instance the lists maintained by W3C at ConverterToRdf, RDFImportersAndAdapters (outdated), and RdfAndSql, or perform a quick Google search.
However, finding the right tool for a particular scenario can be difficult and time-consuming. A user needs to try the tool and invest some time in understanding it, while its limitations may only be discovered later. Many tools are limited to a particular input format or come with a particular application; are no longer supported, maintained or suffer from bugs; need a significant time investment to learn the specifics of their use or configuration options; or lack sufficient documentation.
This recipe aims to address these problems by presenting a selection of conversion tools, and giving guidance on choosing the right tool, that adhere to the following (somewhat subjective) criteria:
Generic applicability (e.g. not limited to OWL or SKOS)
Multiple formats: tabular (Excel, CSV etc), hierarchical (XML, JSON), RDBs
Well documented
Actively maintained
Easy to install and use (i.e. no compilation or docker needed)
Reasonably stable/bug free
Available for all major platforms (Windows, Mac, Linux)
14.6. Step by step process¶
14.6.1. Step 1: consider requirements¶
To choose the best tool for your conversion task consider the following:
Is a GUI preferred, or a command line interface? Should it be possible to automate the conversion?
Should the mapping be reused (repeated)? Should mappings be defined in an open standard independently from a particular tool?
Is the data messy or does it require significant transformation before conversion?
Might it be better to present the data as a virtual graph (mainly for databases) than performing an actual conversion?
Based on these criteria, find the right tool in the table below. Jump to the section on that tool to read about additional considerations and details.
GUI |
CLI, automation |
Reuse mappings |
Messy data |
Virtual graph |
|
|---|---|---|---|---|---|
OpenRefine + RDF extension |
✅ |
+/- |
+/- |
✅ |
|
Tarql: SPARQL for Tables |
✅ |
+/- |
|||
TopBraid Composer (ME)1 |
✅ |
||||
RML-based tools (RML mapper, SDM-RDFizer) |
✅ |
✅ |
|||
SPARQL-Generate |
✅ |
✅ |
|||
Ontop (RDB only) |
✅ |
✅ |
✅ |
||
Virtuoso (proprietary tool) |
✅ |
✅ |
|||
Custom code |
✅ |
✅ |
Except for OpenRefine and writing your own code, most tools make use of a mapping language to declare the rules for conversion to RDF. Read the section on transformation/mapping languages to find out more about these languages and why it makes sense to prefer YARRRML as the mapping language of choice.
14.6.2. Step 2: select/install tool¶
Select one or more tools to install and evaluate, go through the tutorials, and try the tool for conversion of a small selection of your data.
14.7. Tools¶
14.7.1. OpenRefine with RDF extension¶
OpenRefine is an open source data transformation tool for exploring, cleaning, and transforming all kinds of structured data. It offers a spreadsheet-like user interface that allows users to interactively explore and transform their data. Data can be manipulated through menu actions and GREL (Google Refine Expression Language) or Python/Jython expressions. It keeps a undo/redo history which can also be used to ‘replay’ transformation and configuration steps.
OpenRefine is open source and has an active community. Additional functionality is provided through extensions and custom distributions. For instance, the ability to work with RDF is provided by installing the RDF extension. Publication to FAIR data points is provided through the FAIR metadata extension.
When you should use this application:
When you are more familiar with working with a user interface and not so much with configuration scripts or coding, and want to interactively explore and manipulate your data
When you have data that needs some manipulation, i.e. messy data, before conversion to RDF
Installation:
For working with RDF, a plugin is needed.
It is possible to use a distribution of openrefine that comes prepackaged with this plugin and other useful features. However, this package is not maintained anymore.
It is therefore advised to download the latest version of OpenRefine and RDF plugin and install the plugin yourself.
Details:
Tutorial(s), see OpenRefine Foundation course, screencast, curated list
Input format(s): Excel, CVS/TSV, XML, JSON, (relational) databases
It is possible to automate, see FAQ
Complex manipulation of data is possible with GREL or Python (Jython) expressions
It is possible to reuse mappings through exporting part of the undo/redo history that led to the RDF export, see replaying operations
Installing the RDF extension:
Download on GitHub (wiki)
Enables graphical mapping of data to an RDF skeleton for export (with autocomplete)
Import and export to Turtle and RDF/XML
Query against a Sparql endpoint
Notes on how to install extensions: install extensions
14.7.1.1. OpenRefine metadata extension¶
The OpenRefine metadata extension adds support for uploading metadata of a dataset to a so-called FAIR Data Point (FDP). A FDP is a metadata repository that provides access to metadata in a FAIR way. This extension can be used in conjunction with the RDF extension.
14.7.2. Transformation/mapping languages¶
Some users may favor a text-based approach over a graphical tool. In addition, graphical tools may come with several disadvantages: mapping and generation is tied to that particular application, exchange of mappings (between users or applications) may be difficult, and automation or integration in a built pipeline may not be possible.
A more flexible approach is offered by transformation or mapping languages. These languages allow to declare mappings and RDF generation independent from a particular application.
14.7.2.1. D2RQ¶
D2RQ is a mapping language to describe direct mappings between the tables and columns of a relational database (RDB) to classes and properties.
14.7.2.2. R2RML¶
A well-known mapping language is R2RML (RDB to RDF Mapping Language), which is an RDF vocabulary to describe mappings from relational databases to RDF. R2RML is an official W3C recommendation and is supported by many tools.
14.7.2.3. RML¶
RML (Rule markup Language) is a mapping language that extends R2RML to also support mappings from other structured formats such as CSV and JSON (it is a superset of R2RML).
Online graphical editor for creating RML mappings: RMLEditor (beta, with some size limitations)
Downside of RML and R2RML is that they are designed to be processed by machines: manual definition of rules using these RDF vocabularies is complex, time-consuming, and comes with a steep learning curve. To address these problems, the mapping language YARRRML was created.
14.7.2.4. YARRRML¶
YARRRML is a human-readable text-based representation for generation rules that can be directly translated to RML. It is a subset of YAML, which is a human-friendly data serialization standard that is commonly used for configuration files.
YAML uses Python-style indentation to indicate nesting (no tabs), has compact notations for lists and maps and is a superset of JSON. YARRRML hides the complexity of machine-processable rules while it remains interoperable with existing tools.
There’s an online YARRRML editor/playground called Matey that allows you to interactively edit YARRRML files and see the results of the conversion on a small sample dataset. It also exports YARRRML as RML and R2RML.
A YARRRML parser is also available (GitHub, download) that converts to RML/R2RML so that mapping/translation rules can be executed by any tool that accepts RML/R2RML.
Defining your mappings in YARRRML is advisable, considering it’s easy to understand and can be converted to RML or its subset R2RML, used by many tools for declarative mappings.
14.7.3. RML-based tools¶
14.7.3.1. RMLMapper¶
RMLMapper is the reference implementation for RML-based mapping tools. It has the option to generate PROV-O metadata for the conversion, suitable as FAIR metadata. Although easy to use/configure, it has the downside that it loads all data in memory, which means there is a limit on the size of the data that can be converted.
Download: rmlmapper-java releases
14.7.3.2. SDM-RDFizer¶
SDM-RDFizer is a Python-based tool which is similar to RMLMapper but is suited for large datasets. It requires some additional configurations for settings like intermediary file locations.
For download and instructions, see SDM-RDFizer (GitHub).
14.7.4. Morph-KGC¶
Morph-KGC is a powerful engine to generate RDF and RDF-star knowledge graphs. It supports a wide range of relational databases and data file formats. It scales to large volumes of data and runs from the command line or as a python library (creating RDFLib or Oxigraph graphs). It is also integrated in kglab, an abstraction layer for working with knowledge graphs using popular libraries.
Download: Morph-KGC.
Documentation: readthedocs.
14.7.4.1. Other RML-based tools¶
There are other RML-based conversion tools that are more tailored to particular scenarios, for instance RMLStreamer for streaming data. For an overview of feature completeness of tools, see the RML Implementation Report.
14.7.4.2. SPARQL-Generate¶
SPARQL-Generate is a template-based language for generating RDF streams from a range of input formats, such as tabular data, JSON, XML, and relational databases. It extends SPARQL 1.1, which means it should feel familiar for everyone already familiar with SPARQL queries.
To quickly write and test queries (on small datasets), use the SPARQL-Generate Playground web-application.
The SPARQL-Generate executable jar is a CLI (command line interface) tool for executing SPARQL-Generate queries.
14.7.5. Virtual graph¶
Tools that dynamically render a relational database as virtual RDF graph.
14.7.5.1. Ontop¶
Ontop is a virtual knowledge graph system for arbitrary databases. It has its own mapping language but also supports R2RML. It runs as a command line tool, but there is also an Ontop plugin for Protégé to define mappings and import triples using a GUI application.
Although triples are exposed as a virtual graph, it is possible to export to RDF using a ‘materialize’ command.
14.7.6. Proprietary tools¶
A proprietary tool is a commercial tool for which licenses need to be obtained
14.7.6.1. TopBraid Composer¶
TopBraid Composer Maestro Edition (commercial license) is an Integrated development environment (IDE) for working with semantic web technologies, such as RDF and OWL. It has support for converting a range of formats to RDF, including tabular/spreadsheet data, XML, JSON, and RDB. It uses a straightforward conversion to RDF, which doesn’t allow for extensive customization: sheets and tabular data are directly mapped to a spreadsheet ontology, XML directly according to an XML vocabulary, and relational databases are mapped using direct mapping with D2RQ.
The resulting RDF directly reflects the structure and schema of the database. However, once loaded as RDF, transformations and elaborate mappings can be applied using TopBraids visual scripting language SPARQLMotion, or SPIN/Sparql construct queries.
14.7.6.2. Virtuoso Universal Serve¶
Virtuoso Universal Server is a “universal server” that combines a database engine, web server, triple/quat store, and more. It powers many nodes of the Linked Open Data cloud, for instance dbpedia.
The Virtuoso “Sponger” (RDFizer) and it’s predefined “cartridges” (containing an Entity Extractor and an Ontology Mapper) are responsible for generating linked data from various forms of data (tabular and RDB). These cartridges are highly customizable, but it is also possible to write new ones. It is also possible to generate linked data views from relational databases using R2RML. Linked data is generated on-the-fly but may be ingested into Virtuoso’s quad store.
There is also an open-source edition available, known as OpenLink Virtuoso.
14.8. Alternative approaches¶
14.8.1. Coding yourself¶
Instead of relying on a tool, most programmers may prefer to write their own conversion code/scripts using their language of choice (e.g. Python, Java). This is probably the fastest, most accessible option because it capitalizes on existing programming skills and avoids the overhead of learning another tool or mapping language. It offers great flexibility: it is highly customizable, any input and output format is possible, and it can be scaled to large datasets. Downside is that it may not be easy to adapt existing code to changing mapping requirements. Also, it may be difficult for others to understand the mapping. In addition, custom code may be susceptible to bugs, while established tools have been tested thoroughly.
Although it is possible to generate RDF by constructing triples using basic string operations, it pays off to use a RDF library for these tasks.
For python there’s the RDFLib package. Working in Jupyter notebooks with one of the common data manipulation libraries (e.g. pandas) allows you to interactively explore and manipulate the data before converting it into RDF.
For Java the two most common libraries for working with RDF are Apache Jena and Eclipse RDF4J.
14.9. What to read next?¶
Learn more about:
FAIRsharing records appearing in this recipe:
- Comma-separated Values (CSV)
- Extensible Markup Language (XML)
- FAIR Data Point (FDP)
- GitHub
- JavaScript Object Notation (JSON)
- Resource Description Framework (RDF)
- Simple Knowledge Organization System (SKOS)
- Simple Protocol and RDF Query Language Overview (SPARQL)
- Tab-separated values (TSV)
- Terse RDF Triple Language (Turtle)
- The FAIR Principles (FAIR)
- W3C Provenance Ontology (PROV-O)
- Web Ontology Language (OWL)
- Zenodo
References
14.10. Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
The Hyve |
Writing - Original Draft |
||||
The Hyve |
Writing - Review & Editing |
||||
The Hyve |
Writing - Review & Editing |