5. Depositing to generic repositories - Zenodo use case¶

5.1. Main Objectives¶
The main purpose of this recipe is:
To show how to take advantage of CERN Zenodo repository to document the existence of datasets, thus increasing its findability. This is of particular relevant for IMI projects since Zenodo is aimed to support the European Commission (EC) nascent Open Data policy and is commissioned by the EC.
5.3. Introduction to Zenodo repository¶
5.3.1. What is Zenodo?¶
Zenodo is a repository developed by CERN under the OpenAire program, the focus of which is on open data. It was commissioned by the EC to support their nascent Open Data policy by providing a catch-all repository for EC funded research. This of particular relevance for all projects funded under the Innovative Medicine Initiative (IMI).
5.3.2. Why use Zenodo?¶
To cite Zenodo's documentation, here are a few reasons why using the repository services provides a low entry barrier to making data findable:
Safe — your research is stored safely for the future in CERN’s Data Centre for as long as CERN exists.
Trusted — built and operated by CERN and OpenAIRE to ensure that everyone can join in Open Science.
Citeable — every upload is assigned a Digital Object Identifier (DOI), to make them citable and trackable.
No waiting time — Uploads are made available online as soon as you hit publish, and your DOI is registered within seconds.
Open or closed — Share e.g. anonymized clinical trial data with only medical professionals via our restricted access mode.
Versioning — Easily update your dataset with our versioning feature.
GitHub integration — Easily preserve your GitHub repository in Zenodo.
Usage statisics — All uploads display standards compliant usage statistics.
5.4. 1. How to use Zenodo Deposition Web Interface?¶
This section guides users through the key steps to perform to organize a deposition to Zenodo using the user interface web component provided by the repository.
5.4.1. Zenodo Compatible Data Collection - Login-in¶
Login via ORCID or Github credentials
5.4.2. Zenodo Compatible Data Collection - Data upload¶
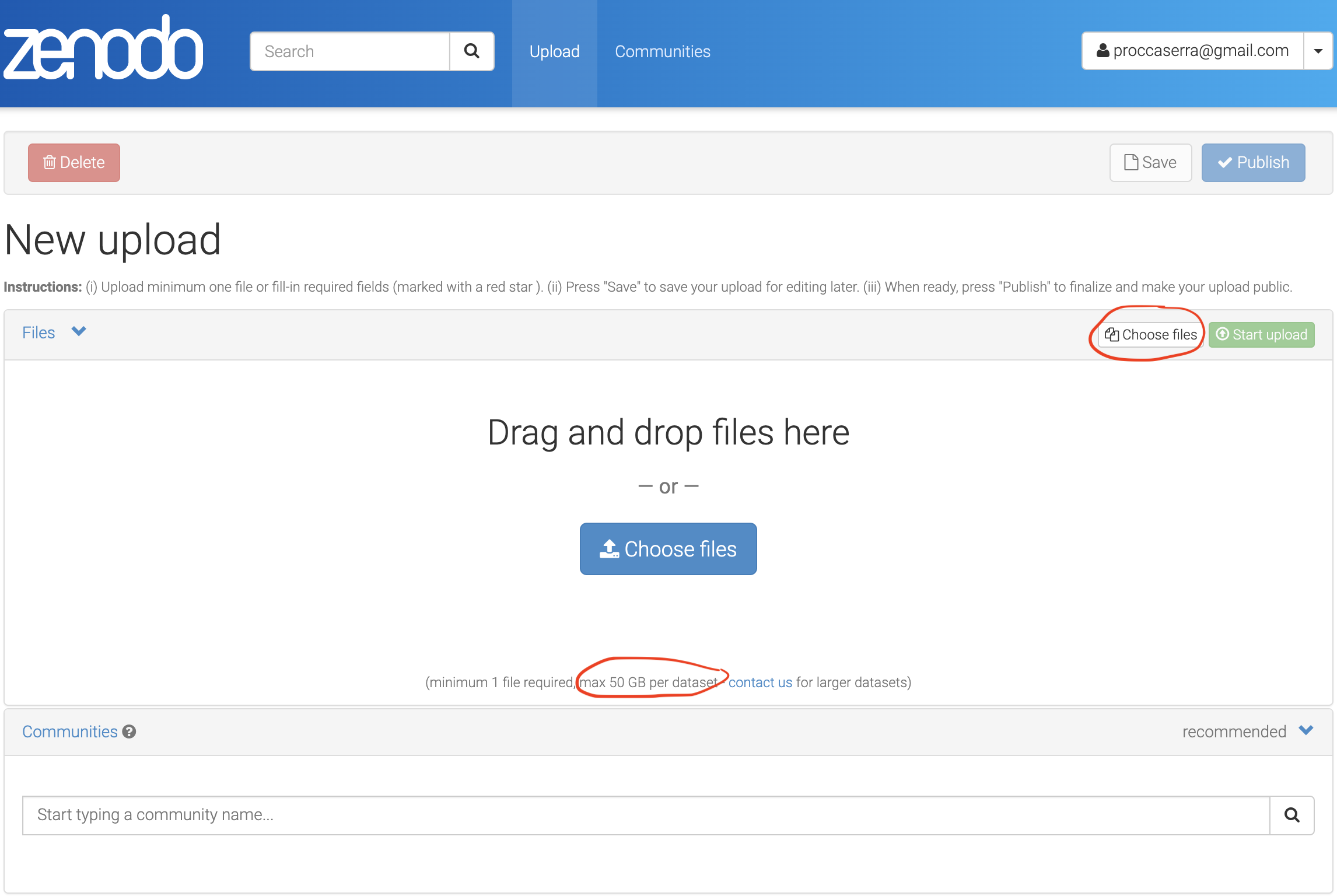
Fig. 5.2 Uploading files to Zenodo Repository.¶
Files can be dragged and dropped, with the following limitations:
5GB max each,
50 GB total / dataset
After adding the set of files associated with the submission, the upload should be initiated by pressing the start upload green button.
Failing to do so will result in a failure to proceed with the submission and an error will be thrown, reminding users to do so.
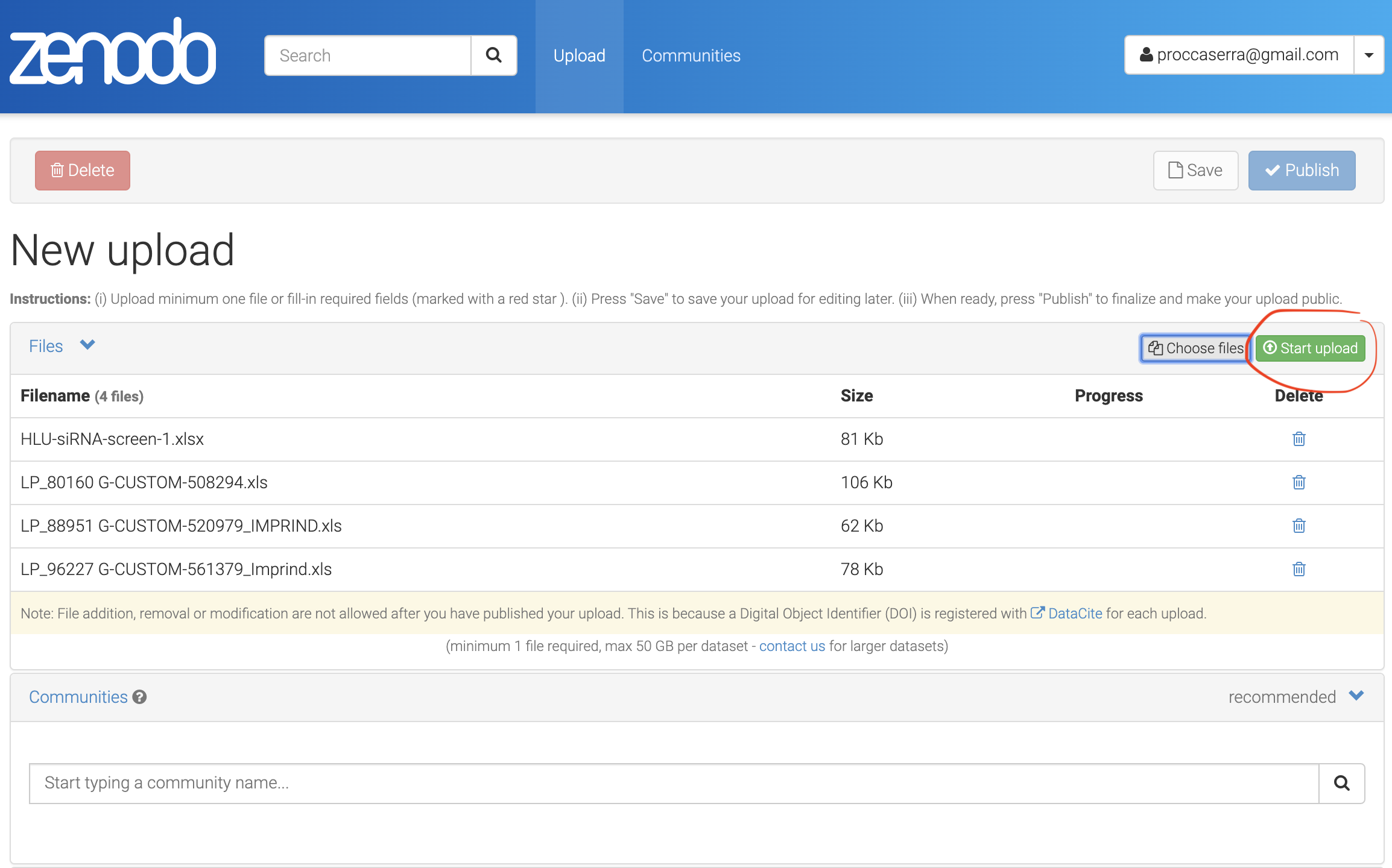
Fig. 5.3 Starting the file upload to Zenodo Repository.¶
The next key step is to select the upload type. In this instance, the Dataset is selected. This matters as it provide strong typing which is relied on by search engine and therefore impacts findability.

Fig. 5.4 Selecting the upload type to Zenodo Repository.¶
5.4.3. Zenodo Compatible Data Collection - Providing Metadata¶
Basic metadata such as.
title,description, at minima should be provided.Authors should be identified, ideally using their
orcid, so linking can be performed. This affects authors citation and impact evaluation. For IMI FAIRplus participants, since all have now such an identifier, the link should be made systematically.
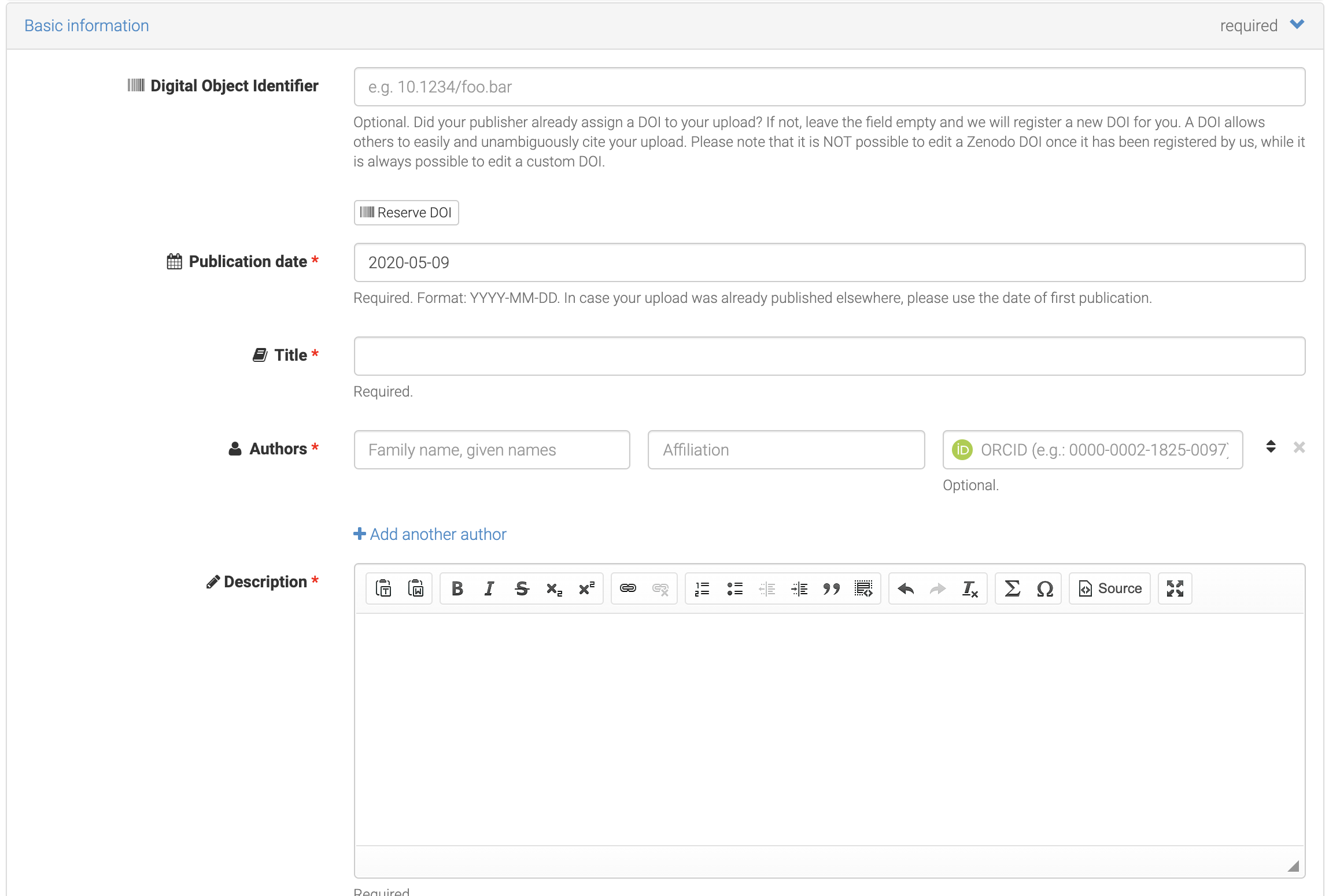
Fig. 5.5 Basic metadata to report .¶
Reserve a Digital Object Identifier: This is a service provided natively by the Zenodo service, by virtue of its integration with Datacite services. This is quite an important point as it means the Zenodo submission can be cited. However, remember to carefully review all the data entered in the form as once a doi has been minted, the associated information can not be changed without creating a new version of the archive and therefore minting a new doi
‘Keywords’ can be added to tag the submission. These are free text and no controlled terminology can be used in the interface at the moment.
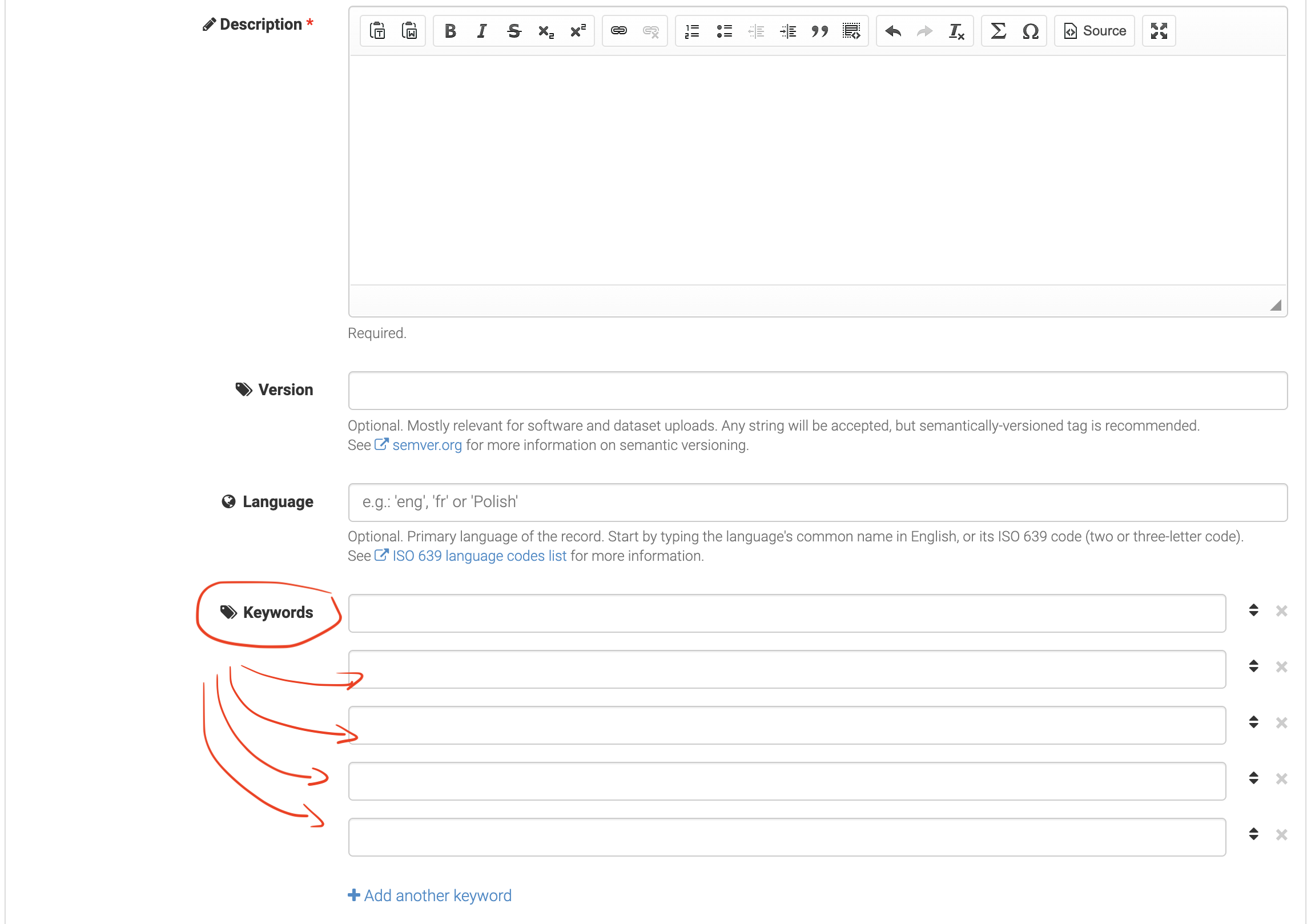
Fig. 5.6 Setting keywords associated with the Zenodo deposition .¶
5.4.4. Zenodo Compatible Data Collection - Access and License information¶
Zenodo provides facilities to set
Access ConditionsandLicense,Data Controler Contact Information, as well asEmbargo Durationif applicable.As indicated above, it is possible to
set an Embargo Period, if the optionembargoed accessis selected under theAccess rightsection.
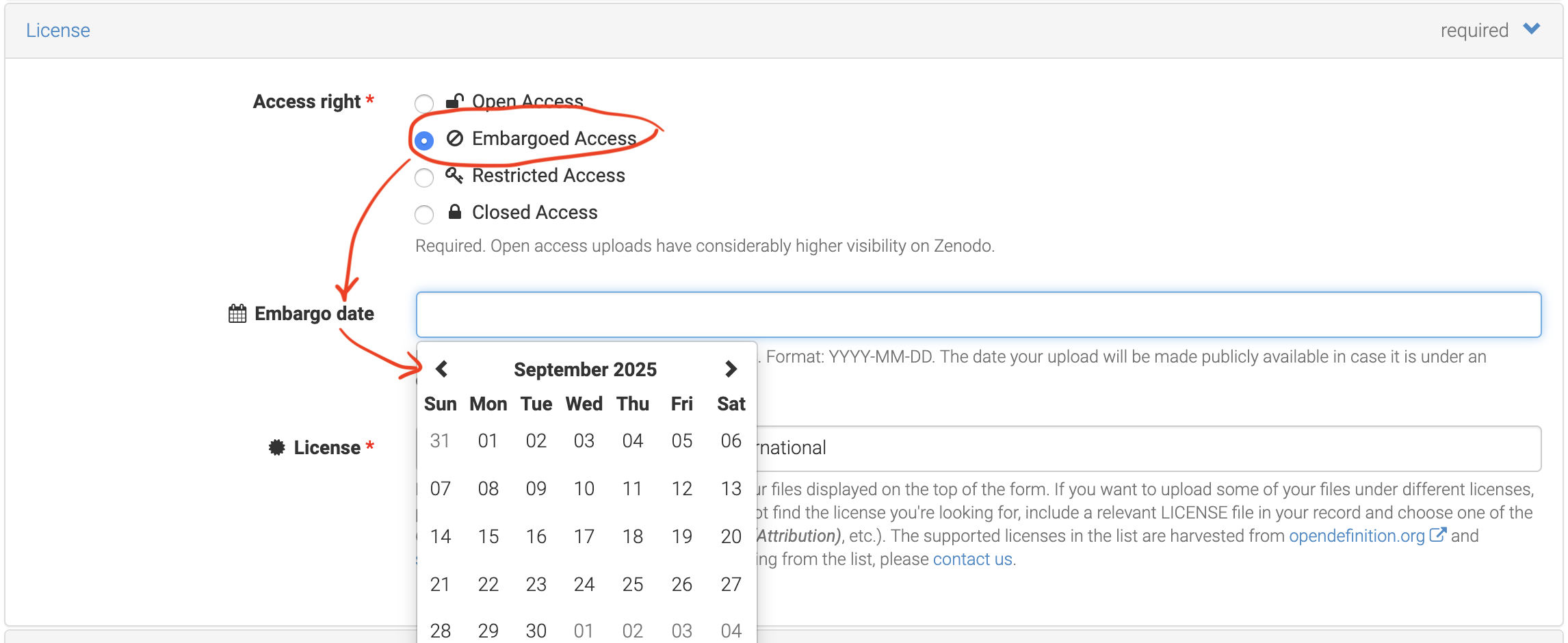
Fig. 5.7 Choosing a License is essential.¶
Zenodo places no limit when it comes to duration of the embargo period. So submitters should check EC and IMI guidelines or local institutional requirements for guidance.
Setting Access Conditions/License, Data Controler Contact Information, Embargo Duration if applicable
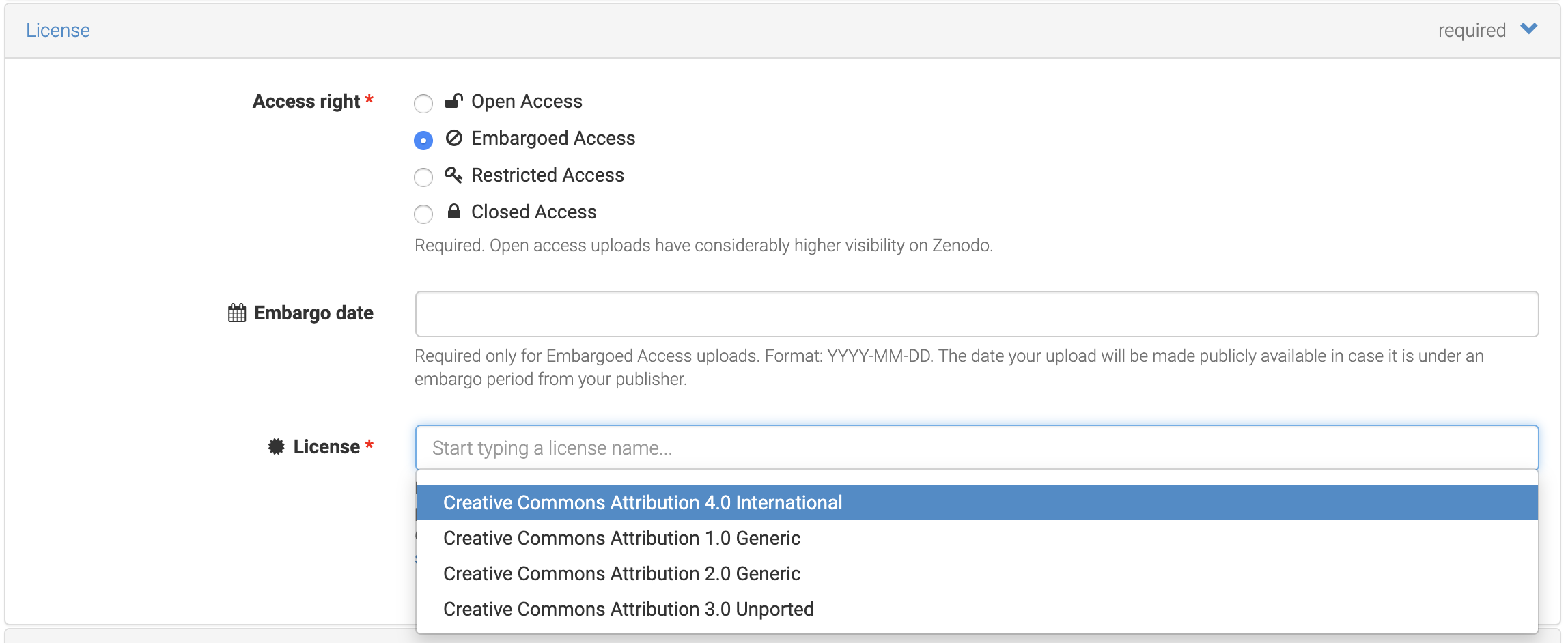
Fig. 5.8 Setting access conditions.¶
Start typing to display more licenses available from Zenodo

Fig. 5.9 Autocompletion prompts available licenses.¶
5.4.5. Zenodo Compatible Data Collection - Funding Information¶
Since the Zenodo mission is to collect EC funded data, the repository provides the means to lookup Grant Information:
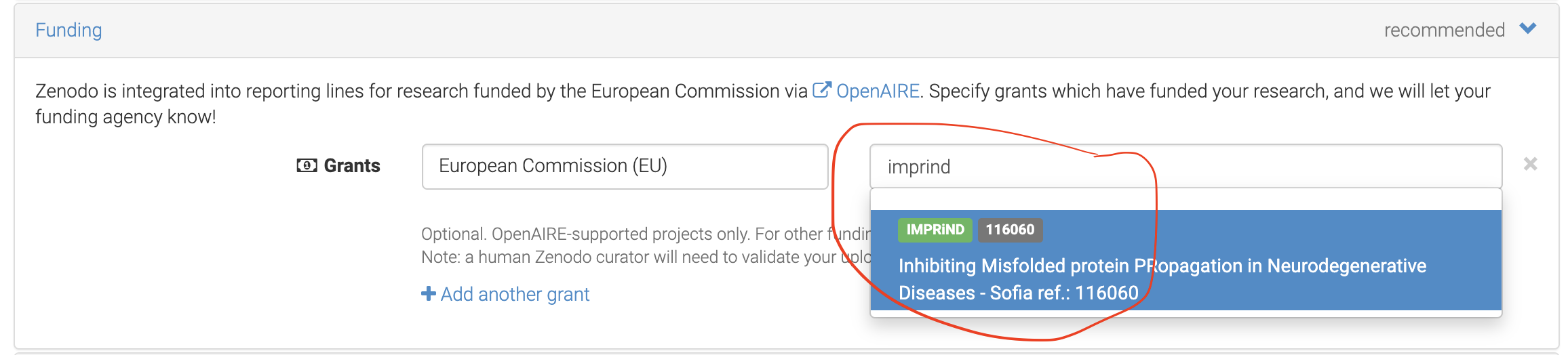
Fig. 5.10 Linking Funding to Zenodo Submission.¶
Zenodo: openAIRE connected repository
Connected to funding agencies
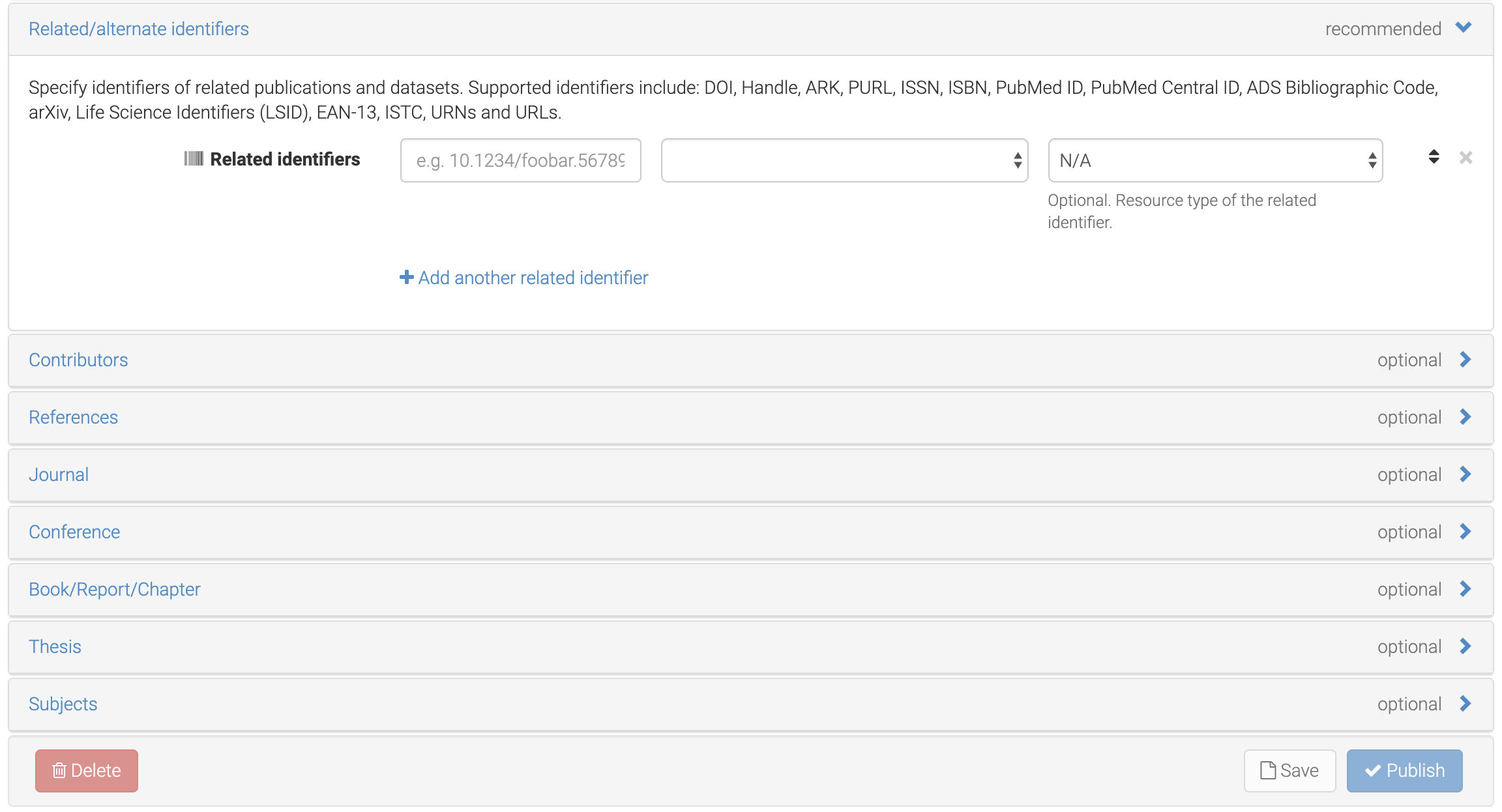
5.5. 2. Programmatic Deposition to Zenodo via the REST-API¶
5.5.1. Create a zenodo account and obtain an API token¶
First, it is necessary to obtain an api key:
ACCESS_TOKEN= “<enter-your_writeonly_token_for_testing or your_deposit_token if you want to get a DOI >”Then, the following code invoking the Zenodo REST endpoint will allow deposition:
import requests import json zenodo_baseurl = "https://zenodo.org/api/" headers = {"Content-Type": "application/json"} ACCESS_TOKEN = "<YOUR_TOKEN_GOES_HERE>" # testing the connection r = requests.get("https://zenodo.org/api/deposit/depositions", params={"access_token": ACCESS_TOKEN}) # creating an empty submission to get an zenodo record id: r = requests.post('https://zenodo.org/api/deposit/depositions', params={'access_token': ACCESS_TOKEN}, json={}, headers=headers) r.status_code # obtain the zenodo metadata payload as json containing the id r.json()
5.5.2. Create the payload for the programmatic deposition¶
For example, it can be obtained by parsing the content of a metadata template or from a dedicated acquisition form specifically made by a
data manager# getting the record id deposition_id = r.json()['id'] # uploading the data data = {'filename': 'rose-aroma-naturegenetics2018-treatment-group-mean-sem-report-datapackage.json'} files = {'file': open('../data/processed/rose-data/rose-aroma-naturegenetics2018-treatment-group-mean-sem-report-datapackage.json', 'rb')} r = requests.post('https://zenodo.org/api/deposit/depositions/%s/files' % deposition_id, params={'access_token': ACCESS_TOKEN}, data=data, files=files) r.status_code
Forming the augmented data payload for a dataset corresponding to the JSON data package for the matrix
metadata = { "metadata": { "title": "Frictionless Tabular data package for GC-MS data from Rose Genome article published\ in Nature genetics, June, 2018", "upload_type": "dataset", "description": "This dataset, in the form of a Frictionless Tabular Data Package \ (https://frictionlessdata.io/specs/tabular-data-package/), \ holds the measurements of 61 known metabolites (all annotated with resolvable CHEBI identifiers and InChi), \ measured by gas chromatography mass-spectrometry (GC-MS) in 6 different Rose cultivars (all annotated with \ resolvable NCBITaxId) and 3 organism parts (all annotated with resolvable Plant Ontology identifiers).\ The data was extracted from a supplementary material table, available from \ https://static-content.springer.com/esm/art%3A10.1038%2Fs41588-018-0110-3/MediaObjects/41588_2018_110_MOESM3_ESM.zip \ and published alongside the Nature Genetics manuscript identified by the following doi: \ https://doi.org/10.1038/s41588-018-0110-3, published in June 2018. \ This dataset is used to demonstrate how to make data Findable, Accessible, Discoverable and Interoperable" \ "(FAIR) and how Tabular Data Package representations can be easily mobilized for re-analysis and data science. \ It is associated to the following project available from github at: \ 'https://github.com/proccaserra/rose2018ng-notebook' with all necessary information and Jupyter notebooks.", "creators": [ { "affiliation": "University of Oxford", "name": "Philippe Rocca-Serra", "orcid": "0000-0001-9853-5668" }, { "affiliation": "University of Oxford", "name": "Susanna Assunta Sansone", "orcid": "0000-0001-5306-5690" } ], "access_right": "open", "keywords": [ "FAIR data", "Design of Experiment", "Rose scent", "targeted metabolite profiling", "gas chromatography mass spectrometry", "Tabular Data Package", "STATO ontology", "ISA format", "interoperability"], "language": "eng", "license": { "id": "CC-BY-4.0" }, "publication_date": "2019-03-13", "references": ["https://doi.org/10.1038/s41588-018-0110-3"], "related_identifiers": [ { "relation": "cites", "identifier": "10.1038/s41588-018-0110-3" }, { "relation": "cites", "identifier": "10.5281/zenodo.2598799" }, { "relation": "isNewVersionOf", "identifier": "10.5281/zenodo.2557893" } ], "grants": [{"links":{"self":"https://zenodo.org/api/grants/10.13039/501100000780::654241"},"acronym": "PhenoMenAl", "program": "H2020", "funder": { "doi": "10.13039/501100000780", "acronyms": [ "EC" ], "name": "European Commission", "links": { "self": "https://zenodo.org/api/funders/10.13039/501100000780" } } }] } } r = requests.put("https://zenodo.org/api/deposit/depositions/%s" % deposition_id, params={"access_token": ACCESS_TOKEN}, data=json.dumps(metadata), headers=headers) r.status_code
5.5.3. Finalize request and post¶
Finally, combine metadata and data payload in order to send a properlly formed request and obtain a DOI.
data_2 = {'filename': 'rose-aroma-naturegenetics2018-treatment-group-mean-sem-report-table-example.csv'}
files_2 = {'file': open('../data/processed/rose-data/rose-aroma-naturegenetics2018-treatment-group-mean-sem-report-table-example.csv', 'rb')}
r = requests.post('https://zenodo.org/api/deposit/depositions/%s/files' % deposition_id,
params={'access_token': ACCESS_TOKEN}, data=data_2,
files=files_2)
r.status_code
5.6. Conclusions¶
Relying on CERN Zenodo repository using any of the submission mechanisms (either web component or API) is one the simplest yet highly effective ways to deliver dataset findability for assets generated by publicly funded resources. The integration with ORCID makes it very easy to obtain an account on CERN’s service. The integration with Datacite means that submitters can reserve and obtain Digital Object Identifiers (DOI) very simply. These can then be cited and used as references to the datasets. The integration with Crossref means that funding information case be easily looked up, thus reducing data entry burden in most conditions but especially for EU funded projects such as IMI. Licensing information can also be easily supplied. Data access and embargo dates can be reserved. Findability via search engines is enhanced as Zenodo supports content negotiation, serving schema.org based JSON-LD documents. Users should however be reminded of the following limitations of the service:
Absence of constraints on the nature of the datafiles being uploaded.
No domain specific awareness and domain specific metadata.
Absence of connection with specialized repositories.
Size limitation for a given datasets.
5.7. References¶
References
5.8. Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
University of Oxford |
|
Writing - Writing, Conceptualization |
|||
University of Oxford |
|
Writing - Review & Editing, Funding acquisition |