3. Oncotrack - observational clinical cohort datasets¶

3.1. Ingredients¶
Metadata model
Vocabularies and terminologies
Pharmaceutical drug names follow the nomenclature of ChEBI and ChEMBL database. All drug ontologies are listed here.
All abbreviations and acronyms used in OncoTrack cohort metadata are listed in the OncoTrack public metadata acronym table.
Data format
Input data: Excel
Output data:
tab-delimited text file
JSON file (JSON schema: BioSamples databases JSON schema)
Tools and software
Metadata extract and transform tool: R (Version 3.6.1)
String parsing: R package stringi_1.4.3, stringr_1.4.0
Excel file Loading: readxl_1.3.1
Data structure transform:plyr_1.8.4
JSON format parsing: rjson_0.2.20
JSON schema validator: Elixir JSON schema validator
Ontology mapping: ZOOMA
File Integrity check: md5sum (GNU coreutils) 8.28
3.2. Objective¶
This FAIRification pipeline converts the OncoTrack sample metadata to a structured and consistent data format, improves the findability, interoperability, and reusability of the metadata. The FAIRified metadata provides an enriched context to other Oncotrack derived datasets 1.
3.3. Step-by-Step Process¶
The FAIRification of Oncotrack metadata includes four steps:
accessing the data
metadata extraction, transform and load (ETL) pipeline,
data curation and
data sharing. (Figure 1)
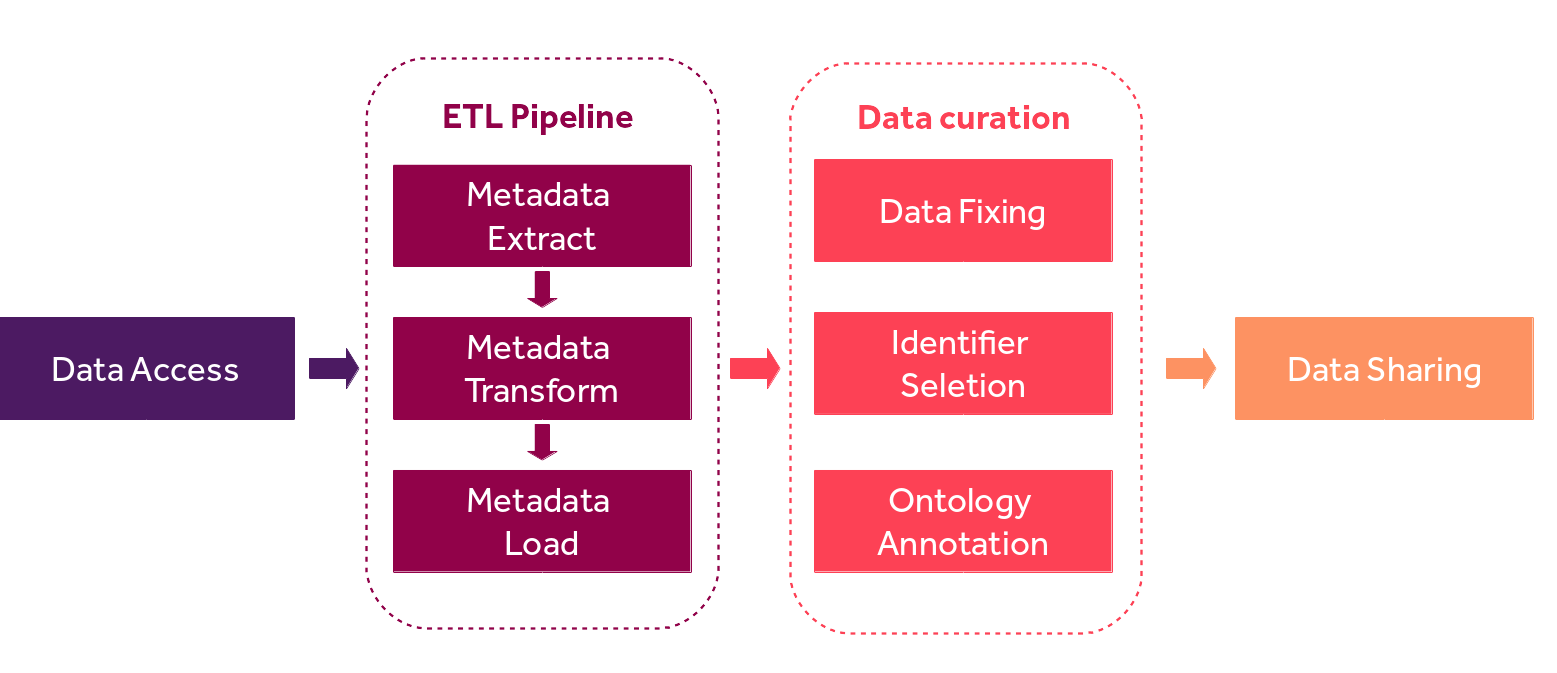
Fig. 3.5 OncoTrack metadata FAIRification pipeline.¶
3.3.1. Data Description¶
The OncoTrack colorectal carcinoma (CRC) biobank includes patient tumour samples, patient derived xenograft models (PDX) and patient-derived 3D cell models (PDO) from 106 patients. Multi-omics experiments and various drug sensitivity studies have been performed on the CRC biobank.
The OncoTrack sample metadata includes published sample metadata, drug sensitivity experiment results, and private cohort information. Here, we focus on the FAIRification of the public sample metadata. Drug sensitivity, as an important property of the patient-derived 3D cell culture models, is also included. The metadata is published on Schütte, et al. Annotations to the metadata are stored inFAIRplus OwnCloud with controlled access.
The original cohort metadata is stored in an Excel spreadsheet. Figure 2 is an example of the cohort metadata. Each sample is listed as a separate row in the spreadsheet. Sample attributes are listed in columns. The sample names follow the OncoTrack identifier system guidelines, which consist of patient ID, tumour type, and patient-derived cell culture model ID. For example, Sample “150_MET1_XEN2” represents “The second xenograft culture of the first metastatic tumour sample in Patient 150.”
_
Fig. 3.6 Example of OncoTrack public cohort metadata.¶
The drug sensitivity data is also provided in Excel spreadsheets. Seventeen drugs are tested on patient-derived organoid(PDO) and patient-derived xenografts(PDX) models in five sets of experiments. Different sets have their unique measurement methods, drug response scales. For example, in Sheet 1: PDO drug response experiment, IC50 value is measured and defines the drug response category (Figure 3a). In Sheet 2: PDX drug response test, the response evaluation criteria in solid tumours (RECIST) scales defines the drug response category (Figure 3b). In both examples, the drug response category is marked by colour codes.
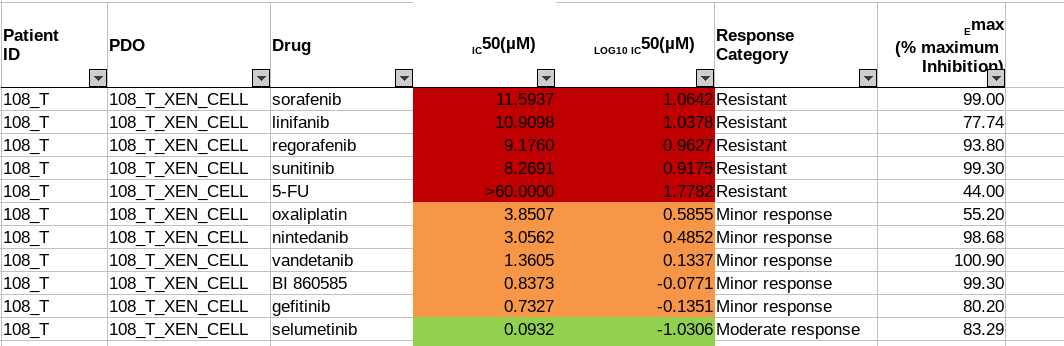

Fig. 3.7 Example of Oncotrack drug response data.¶
3.3.2. Metadata ETL pipeline¶
The frequent use of acronyms and abbreviations in Oncotrack metadata and the inconsistent metadata structures make it difficult to interpret and reuse. To extract and annotate the metadata, the data owner and data curators first agreed on the structure and content of the FAIRified metadata, as well as the principles in metadata extraction.
Firstly, all missing values in the metadata shall be marked with NAs instead of being removed, to facilitate cross-sample comparisons. Secondly, all acronyms and abbreviations shall be expanded to their full forms to avoid ambiguity. Thirdly, the sample attribute values shall correspond to ontology terms if applicable. The final sample metadata template can be found here.
The cohort metadata was converted to a tab-delimited table, of which each row represents one sample, and each column represents one sample attribute. 144 samples from 106 patients were extracted, including 35 organoids and 59 xenografts. Tumour type and sample origin information was retrieved from the sample name. The disease name “colon and rectal cancer” was replaced with ontology term “Colorectal cancer”. Figure 4 is an example of the extracted cohort metadata.

Fig. 3.8 Example of the extracted cohort metadata.¶
Drug sensitivity data were also extracted from the original spreadsheets. Each drug test per sample was listed as one entry. To coordinate different measurement approaches and response category scales, all drug sensitivity data were converted to a unified representation. All the measurement results were stored in Attribute “Value”, the drug response categorizes criteria were stored in Attribute “Unit”, and the drug response category was recalculated and stored in Attribute “Response”. Figure 5 is an example of the extracted drug sensitivity data. 1829 drug tests were extracted in total. The drug response summary is here.

Fig. 3.9 Example of extracted drug sensitivity data.¶
To associate drug sensitivity data with related sample cohort metadata and convert them to machine-readable formats, we combined cohort metadata and drug sensitivity data to JSON files. The BioSamples JSON schema was used as the sample metadata template, allowing direct submissions to BioSamples database and can be easily converted to other formats, like XML, spreadsheets, etc.
The BioSamples JSON schema includes four blocks, submission metadata (e.g. submission domain, release date, update date), administrative metadata, (e.g. contacts, affiliations), general sample metadata (sample names, species, etc) and sample characteristics. All information is stored in key: value pairs. In sample characteristics, only data with flatten structure is accepted.
All cohort metadata and drug sensitivity data of each sample were combined into separate JSON files, named after the original sample identifier.
BioSamples JSON schema only supports strings as value types. Therefore, complex data, for example, drug sensitivity data, need additional parsing to fit into the schema. For each drug response experiments, four descriptive attributes were “Drug Name”, “Value”, “Unit” and “Drug response level” provided. To convert them to key: value pairs, the “drug name” was kept as part of the attribute key. “Value”, “Unit” and “Drug response level” information were joint into one string. For example, the drug response of regorafenib in Sample 302_MET_CELL_XEN (Figure 6) was converted to “Drug response(regorafenib): Minor response, IC50(µM) = 29”. For drugs that were tested more than once, a replicate ID was added to the attribute key.
Administrative information was also added to each JSON object, including institute, project name, and project website. Contact details were not provided, which needs further confirmation from the data owners.
All transformed metadata was validated against BioSamples schema with the Elixir JSON validator, which is based on AJV with additional life science keyword validation.
3.3.3. Data curation¶
Data curation was implemented to increase the findability of the extracted metadata, including ontology mapping, encoding, and fixing data discrepancy.
3.3.3.1. Drug name ontology¶
Different types of drug names were used in the original drug sensitivity data, including generic names, trade names and their chemical names. Some in-development drugs were labelled by their company code. All drug names were mapped to a standardized nomenclature, together with ontology annotations, to increase the findability of drug response results.
The popular drug nomenclatures include International Nonproprietary Names (INNs), DrugBank names, Chemical Entities of Biological Interest (ChEBI) database identifiers, and bioactivity database,ChEMBL identifiers. Among them, the ChEBI database covers most drugs in OncoTrack, is easy to access and has been curated as an ontology source in Open Biomedical Ontology (OBO). Hence, the drug names in ChEBI were selected as the primary drug names. For drugs or active compounds that were not included in ChEBI, their names in ChEMBL were selected.
The OncoTrack drug names were mapped to corresponding ontology terms in ChEBI and ChEMBL using ZOOMA. ZOOMA is an ontology annotation tool, which maps free texts to ontology terms based on a curated repository of annotation knowledge. In OncoTrack drug name mapping, only ChEBI and ChEMBL were selected as ontology sources, and all curation sources except GWAS were selected to improve the coverage and increase the mapping confidence. Figure 6 is an example of the ZOOMA mapping output. Only entries with high mapping confidences were selected. The other entries were mapped manually to terms in ChEBI. Among all 17 drugs, Drug “BI 860585” didn’t map to any pharmaceutical terms, so the original name was kept. The complete mapping results are listed here.
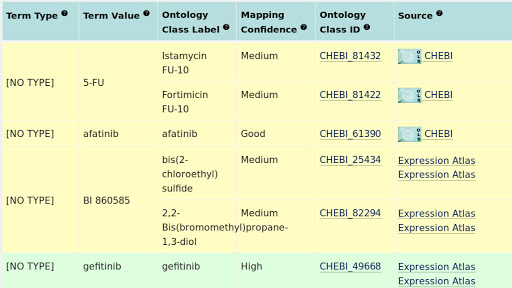
Fig. 3.10 Example of ZOOMA ontology mapping results.¶
3.3.3.2. Data discrepancy¶
Discrepancy and errors were found in the published metadata. In the cohort metadata, the tumour purity of sample “150_MET1”, “208_MET1”, “209_MET2” and “209_T2” were wrongly labelled. We compared these entries with the original records in the OncoTrack database and found discrepancies between the published metadata and Oncotrack database records. Those values were removed from extracted data until further confirmation from the data owner. The updated cohort metadata is here. In drug response metadata extraction, we recalculated the drug response level and found one error in cetuximab drug response level. The corrected drug response data is here.
3.3.4. Data sharing¶
The curated metadata, both in summary spreadsheet format and JSON format, were uploaded to Owncloud and Google drive. The OncoTrack sample metadata can be submitted directly to the EMBL BioSamples database upon request. Supplementary figure 1 is an example of how the metadata will be displayed in the BioSamples database. Checksums were also provided to verify metadata integrity.
3.4. Summary¶
The public cohort metadata and drug sensitivity data were converted to tab-delimited summary files. For each sample, corresponding cohort metadata and drug data were combined to a separate JSON file, which can be later loaded to EBI BioSamples database. Metadata were translated to consistent terminologies and linked with ontology terms.
3.5. Future plan¶
The current ontology annotation is limited to drug names. Other ontologies can be added upon request. More detailed administrative metadata will be added once getting permission from the OncoTrack consortium. The license will be added according to the drug release policy.
3.6. Supplementary materials¶
Supplementary materials
Script 1: Extract_cohort_metadata.R
Script 2: Extract_drugResponse_metadata.R
Script 3: Transform to JSON.R
Supplementary figure 1: Example of Sample 150-MET1-XEN2 in BioSamples database
3.7. References¶
References
- 1
M. D. Wilkinson, M. Dumontier, I. J. Aalbersberg, G. Appleton, M. Axton, A. Baak, N. Blomberg, J. W. Boiten, L. B. da Silva Santos, P. E. Bourne, J. Bouwman, A. J. Brookes, T. Clark, M. Crosas, I. Dillo, O. Dumon, S. Edmunds, C. T. Evelo, R. Finkers, A. Gonzalez-Beltran, A. J. Gray, P. Groth, C. Goble, J. S. Grethe, J. Heringa, P. A. ‘t Hoen, R. Hooft, T. Kuhn, R. Kok, J. Kok, S. J. Lusher, M. E. Martone, A. Mons, A. L. Packer, B. Persson, P. Rocca-Serra, M. Roos, R. van Schaik, S. A. Sansone, E. Schultes, T. Sengstag, T. Slater, G. Strawn, M. A. Swertz, M. Thompson, J. van der Lei, E. van Mulligen, J. Velterop, A. Waagmeester, P. Wittenburg, K. Wolstencroft, J. Zhao, and B. Mons. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data, 3:160018, Mar 2016.
3.7.1. What to read next?¶
FAIRsharing records appearing in this recipe:
3.8. Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
EMBL-EBI |
|
Writing - Original Draft |