5. Provenance information¶

5.1. Main Objectives¶
In all tasks of data integration, especially in the area of Pharma, ensuring trust in data sources is essential. The steps taken to ensure new datasets or sources of information meet a number of criteria ascertaining some level of quality are many. One of them is a check on the origin of the information, in other words, its Provenance. Provenance covers the elements detailing how the data was produced by identifying the agents (human, software, workflows) so a certain level of traceability and accountability can be established. The notions of audit and trail as well as versioning and authorship are essential to be able, should any distortion be identified in downstream analysis, to trace back to possible sources of error.
5.2. Provenance: a definition¶
“Provenance is information about entities, activities, and people involved in producing a piece of data or thing, which can be used to form assessments about its quality, reliability or trustworthiness”. Provenance has been an active field of academic research and several models have been developed over the year to cover the domain. The next section will introduce the most known models as well as detail how their overlap and what are the differences between these.
Data provenance is also referred to as data lineage
5.2.1. OPM Open Provenance Model¶
Published in 2011, the Open Provenance Model (OPM) 8 was the first formal model developed to cater for the reporting of provenance information with several main goals in mind:
provide a domain agnostic, formal and actionable definition of provenance
enable sharing of provenance information between systems, an issue of interoperability
support tool development and implementation
enable validation of provenance messages.
The work was well-received and several workshops and working groups refined the specification which resulting in a specification being submitted to the World Wide Web Consortium. The following sections provides further insights into these efforts.
5.2.2. The PROV Data Model¶
This definition is taken from the W3C Provenance Data Model specifications 1.
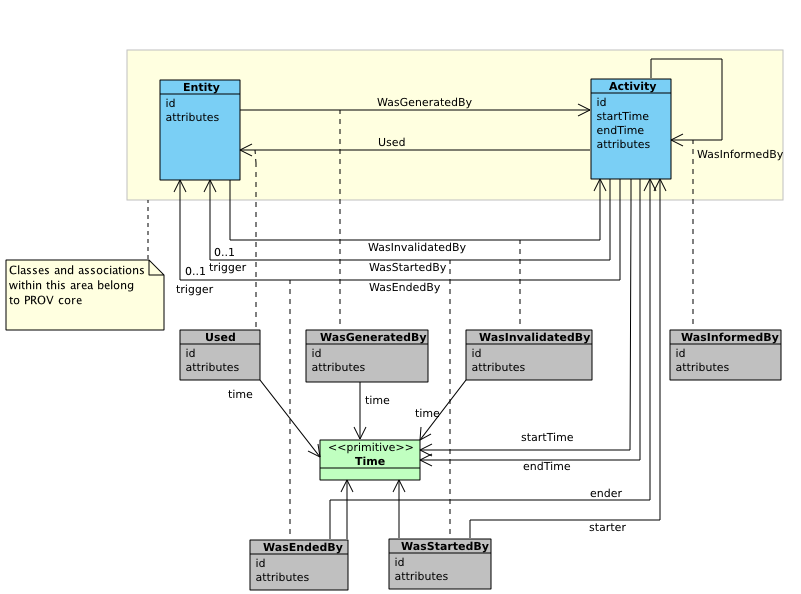
Fig. 5.13 Overview of the Provenance Data Model main classes.¶
5.2.3. PROV vocabulary:¶
The PROV-O Provenance Ontology 2 is a W3C-vetted specification of the Provenance Data Model as an OWL ontology. The namespace for PROV-O is http://www.w3.org/ns/prov#. It is meant to allow expressing provenance information as modeled in the provenance model W3C PROV-DM with Classes, Properties and relations defined in the W3C Ontology Web Language (OWL). Instances can therefore be represented in RDF and distributed in any of the official serialization, e.g. JSON-LD, RDF/XML, Turtle.

Fig. 5.14 Overview of the Provenance Ontology main classes.¶
Below is an example of provenance information represented using the PROV-O ontology and serialized as RDF statements using turtle representation.
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix prov: <http://www.w3.org/ns/prov#> .
@prefix : <http://example.org#> .
:bar_chart
a prov:Entity;
prov:wasGeneratedBy :illustrationActivity;
prov:wasDerivedFrom :aggregatedByRegions;
prov:wasAttributedTo :derek;
.
:derek
a foaf:Person, prov:Agent;
foaf:givenName "Derek";
foaf:mbox <mailto:derek@example.org>;
prov:actedOnBehalfOf :natonal_newspaper_inc;
.
:national_newspaper_inc
a foaf:Organization, prov:Agent;
foaf:name "National Newspaper, Inc.";
.
:illustrationActivity
a prov:Activity;
prov:used :aggregatedByRegions;
prov:wasAssociatedWith :derek;
prov:wasInformedBy :aggregationActivity;
.
:aggregatedByRegions
a prov:Entity;
prov:wasGeneratedBy :aggregationActivity;
prov:wasAttributedTo :derek;
.
:aggregationActivity
a prov:Activity;
prov:startedAtTime "2011-07-14T01:01:01Z"^^xsd:dateTime;
prov:wasAssociatedWith :derek;
prov:used :crimeData;
prov:used :nationalRegionsList;
prov:endedAtTime "2011-07-14T02:02:02Z"^^xsd:dateTime;
.
:crimeData
a prov:Entity;
prov:wasAttributedTo :government;
.
:government a foaf:Organization, prov:Agent .
:nationalRegionsList
a prov:Entity;
prov:wasAttributedTo :civil_action_group;
.
:civil_action_group a foaf:Organization, prov:Agent .
5.3. Tools for creating provenance metadata¶
In the previous section, we have detailed the landscape of formal models to represent provenance information. In this section, we will show how tools have implemented these models, or domain-specific extension of them as in the case of computation workflow provenance information.
5.3.1. CamFLow¶
CamFlow is a Linux Security Module (LSM) designed to capture data provenance for the purpose of system audit 9 and aims at capture information flow.
CamFlow support 2 output formats.
W3C PROV-JSON format
"ABAAAAAAACAe9wIAAAAAAE7aeaI+200UAAAAAAAAAAA=": {
"cf:id": "194334",
"prov:type": "fifo",
"cf:boot_id": 2725894734,
"cf:machine_id": 340646718,
"cf:version": 0,
"cf:date": "2017:01:03T16:43:30",
"cf:jiffies": "4297436711",
"cf:uid": 1000,
"cf:gid": 1000,
"cf:mode": "0x1180",
"cf:secctx": "unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023",
"cf:ino": 51964,
"cf:uuid": "32b7218a-01a0-c7c9-17b1-666f200b8912",
"prov:label": "[fifo] 0"
}
Example of a write edge in W3C PROV format:
"QAAAAAAAQIANAAAAAAAAAE7aeaI+200UAAAAAAAAAAA=": {
"cf:id": "13",
"prov:type": "write",
"cf:boot_id": 2725894734,
"cf:machine_id": 340646718,
"cf:date": "2017:01:03T16:43:30",
"cf:jiffies": "4297436711",
"prov:label": "write",
"cf:allowed": "true",
"prov:activity": "AQAAAAAAAEAf9wIAAAAAAE7aeaI+200UAQAAAAAAAAA=",
"prov:entity": "ABAAAAAAACAe9wIAAAAAAE7aeaI+200UAQAAAAAAAAA=",
"cf:offset": "0"
}
Note
CamFlow also concerns itself with a informatics system audit and as obvious from its design, is meanly focused on the security of Linux based systems. The CamFlow framework is highly configurable and allows profiles to be defined. This is a very low level solution and its use remains the confines to information security specialists.
While this tool is probably of limited use to Life Sciences and bioinformatics applications, we mention it for two reasons:
it provides one of the first example of an implementation (even if very basic) making use of the W3C Prov-O model.
it provides an insight on how computational tool can deal with provenance information in ways which allow assessing systems health from a security point of view.
5.3.2. Computational workflows and Provenance information:¶
As seen when introducing the W3C Provenance Data Model and Provenance Ontology, three key entities are necessary to record and track lineage information:
The Entity the origin of which we are concerned with.
The Activity which resulted in the creation of the Entity
The Agent which performed the Activity aforementioned.
Because the PROV model is domain agnostic and very generic, it can be either applied as is, to any situation or it can also be extended and specialized to suit a particular domain on knowledge. To give an example, tracking provenance information in the field of bioinformatics shares features with provenance tracking as used in manufacturing, but it also has a number of specific features. In the field of bioinformatics, where computational pipelines, known as workflows, are assembled to process ever larger datasets on high performance computing infrastructure and cloud infrastructure, having the ability to access data lineage matters for a number for reasons, such as:
audit and trail tasks for regulatory compliance, where every step of the data processing needs to be documented for submission.
resource optimization and energy savings (e.g. should a workflow be executed again or not)
It is those features which have been the focus of an extension as part of the work on computational biology workflows with CWLProv 6, and which we will now cover.
5.3.2.1. Example of CWLProv document¶
The infobox below shows an example of CWLProv RDF document which details how provenance information about the execution of CWL coded workflow may be represented. This document is take from the CWLProv github repository. Such documents are generated and consumed by a feasibility demonstrator tool such as CWLtool
prefix id <urn:uuid:>
prefix provenance <arcp://uuid,73eab018-7b36-4f84-a845-aca8073bd46c/metadata/provenance/>
agent(id:a606d227-bf10-4479-8d11-823bb932bbac,
[prov:type='wfprov:WorkflowEngine', prov:type='prov:SoftwareAgent',
prov:label="cwltool 1.0.20180817162414"])
activity(id:73eab018-7b36-4f84-a845-aca8073bd46c, 2018-08-21T15:20:35.059920, -,
[prov:type='wfprov:WorkflowRun', prov:label="Run of workflow/packed.cwl#main"])
wasStartedBy(id:73eab018-7b36-4f84-a845-aca8073bd46c, -, id:a606d227-bf10-4479-8d11-823bb932bbac, 2018-08-21T15:20:35.060038)
activity(id:e79fc8dc-6e40-4236-b22c-41fee22947a9, -, -,
[prov:type='wfprov:ProcessRun', prov:label="Run of workflow/packed.cwl#main/compile"])
wasStartedBy(id:e79fc8dc-6e40-4236-b22c-41fee22947a9, -, id:73eab018-7b36-4f84-a845-aca8073bd46c, 2018-08-21T15:20:35.163189)
activity(id:e79fc8dc-6e40-4236-b22c-41fee22947a9, -, -,
[prov:has_provenance='provenance:workflow_compile.e79fc8dc-6e40-4236-b22c-41fee22947a9.cwlprov.provn',
prov:has_provenance='provenance:workflow_compile.e79fc8dc-6e40-4236-b22c-41fee22947a9.cwlprov.ttl'
])
Note
Specific recipes about FAIR workflows are available in a specific chapter of the book.
Note
How widely supported are CWLprov documents?
This is very part of academic research, meaning that these specifications demonstrate feasibility and capability.
A number of collaborators of the CWLProv group have included such provenance information in their frameworks.
Tools such as Bagit or specifications such as Research Objects recommended CWLProv documents to be included in
specific folders of the archives when preparing them.
See the BagIt profile for details on the CWLProv folder structure, and the Research Object profile on how to declare the typing of the PROV files.
5.3.2.2. CWLtool: a component to manage workflow information and generate CWLProv information¶
‘cwltool’ for Common Workflow Language tool is a python reference implementation for the Common Workflow Language, which means that it supports the full set of CWL specifications and provides validation functions to check CWL documents.
pip install cwltool
cwltool is not the only implementation of the CWL specifications, others such as Arvados and Toil exist. In case these distinct implementations are also installed on the system, one needs to make sure a helper tool known as ‘cwl-runner’ is also installed. The key function of ‘cwl-runner’ is to allow users to select which CWL implementation will be executed.
pip install cwltool-runner
For the purpose of this recipe, which is to show how provenance information can be generated by a tool such as cwltool 4, users will need to make sure that a workflow is available before performing this conversion.
cwltool --print-rdf --rdf-serializer=turtle mywf.cwl
5.3.2.3. CWLProv-py¶
This tool, also an output from the Common Workflow Language consortium, is solely intended as a validator for provenance information when available from Research Objects 3. It is a standalone python package, which provides a command line interface (CLI) to read, inspect research objects capturing workflow execution information using the CWL syntax.
To install the package, simply run the standard python install package pip:
pip install cwlprov
To run ‘cwlprov’ following installation and using an exemplar CWL file, run the following command:
cwlprov --quiet --directory ./test/1.cwl validate
5.3.3. Provenance and distributed ledger technology¶
With this section, we intend to cover another aspect associated with provenance information. It is the issue of trustworthiness of the information and how to ascertain that even if a provenance information message is valid, it actually contains authentic and untempered information.
The raise of digital currencies such as bitcoin or ethereum has popularized the notion of ‘blockchain’, which is a type of what is known as “distributing ledger technology” (DLT). Blockchains and DLT in general represent technological solution to the problem of trust in provenance. To achieve this goal, DLT relies on three key principles:
distribution of information: in other words, the system is decentralized, meaning that no single entity holds the database. Instead, a multitude of copies of the information are available from a myriad of independent nodes.
transparency: this is a consequence of the distributed nature of the architecture. Transparency is understood as the availability of means of verification by being able to access independent sources of the reference information. This allows consistency checks to be performed and therefore provides the means of tempering detection.
Note
Transparency does not equate open. Some blockchains are public but others are private, for instance to support domain specific applications ranging from financial services, supply chain or other sensitive area such as healthcare information 7.
immutability: this is the last tenet of DLT and refers to the fact that once an entry has been to the distributed ledger, it is digitally signed and synchronized in the network by adding a new element (the block) to the blockchain. Each of the new is digitally signed via some cryptographic algorithm (e.g. Blake2). Any attempt to modify a particular block would result in changing its signature. This can be done but the cost could be prohibitively high as it would entail modifying all subsequent blocks in the chain. This architecture ensures the stability or immutability of the ledger.
Important
This notion of immutability assumes that cryptographic hashes using to digital proof the contracts can not be broken.
The most advanced algorithms somehow guarantee this given the current compute power available. However, it should not be
taken for granted. A situation where cryptographic methods would be breached by disruptive technology such as breakthrough
in quantum computing, are referred to as a cryptographic armageddon as it would wreak havoc on the entire edifice by
allowing to rewrite a ledger, thus voiding trust in an instant 5.
Despite such alarmist claims, quantum computing methods could make attempts to tamper with a ledger impossible,
thus reinforcing the approach.
5.4. Conclusion¶
With this FAIR Cookbook content, we have introduced the notion of Provenance information, providing a brief historical review of the domain model and given a few examples of tools implementing provenance information tracking.
For a more in depth exploration of provenance information, we encourage our readers to follow up with more detailed material listed below:
5.4.1. What to read next?¶
Generating ISA based metadata and packaging it as a research object programmatically
Making workflow information FAIR and depositing to Workflowhub
How to meet community standards for annotation Metadata profile for transcriptomics
Learn more about:
FAIRsharing records appearing in this recipe:
- Common Workflow Language (CWL)
- JavaScript Object Notation for Linking Data (JSON-LD)
- Open Provenance Model (OPM)
- Resource Description Framework (RDF)
- Terse RDF Triple Language (Turtle)
- The FAIR Principles (FAIR)
- W3C Provenance Data Model (PROV-DM)
- W3C Provenance Ontology (PROV-O)
- Web Ontology Language (OWL)
5.5. References¶
Reference
- 1
Provenance data model. URL: http://www.w3.org/TR/prov-dm/.
- 2
Provenance ontology vocabulary. URL: http://www.w3.org/TR/prov-o/.
- 3
Cwlprov-py. URL: https://doi.org/10.5281/zenodo.1471375.
- 4
Cwltool. URL: https://github.com/common-workflow-language/cwltool.
- 5
Cwltool. 2020. URL: https://www.ncsc.gov.uk/whitepaper/preparing-for-quantum-safe-cryptography.
- 6
Farah Zaib Khan, Stian Soiland-Reyes, Richard O Sinnott, Andrew Lonie, Carole Goble, and Michael R Crusoe. Sharing interoperable workflow provenance: a review of best practices and their practical application in cwlprov. GigaScience, 11 2019. giz095. URL: https://doi.org/10.1093/gigascience/giz095, arXiv:https://academic.oup.com/gigascience/article-pdf/8/11/giz095/31149036/giz095.pdf, doi:10.1093/gigascience/giz095.
- 7
Milan Markovic, Naomi Jacobs, Konrad Dryja, Peter Edwards, and Norval J. C. Strachan. Integrating internet of things, provenance, and blockchain to enhance trust in last mile food deliveries. Frontiers in Sustainable Food Systems, 2020. URL: https://www.frontiersin.org/article/10.3389/fsufs.2020.563424, doi:10.3389/fsufs.2020.563424.
- 8
Luc Moreau, Ben Clifford, Juliana Freire, Joe Futrelle, Yolanda Gil, Paul Groth, Natalia Kwasnikowska, Simon Miles, Paolo Missier, Jim Myers, Beth Plale, Yogesh Simmhan, Eric Stephan, and Jan Van den Bussche. The open provenance model core specification (v1.1). Future Generation Computer Systems, 27(6):743–756, 2011. URL: https://www.sciencedirect.com/science/article/pii/S0167739X10001275, doi:https://doi.org/10.1016/j.future.2010.07.005.
- 9
Thomas F. J.-M. Pasquier, Xueyuan Han, Mark Goldstein, Thomas Moyer, David M. Eyers, Margo I. Seltzer, and Jean Bacon. Practical whole-system provenance capture. CoRR, 2017. URL: http://arxiv.org/abs/1711.05296, arXiv:1711.05296.
5.6. Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
University of Oxford |
|
Writing - Original Draft |
|||
University of Luxembourg |
|
Review & Editing |