2. ND4BB - chemical activities datasets¶

Editor’s summary
The authors of this recipe start with data spread over well structured web pages.
They use a KNIME workflow to extract the data into an Excel spreadsheet.
The authors encounter inconsistencies in the web pages, and fix them.
In a separate step, the collected strings were sent through two different ontology annotation APIs. The results are compared.
This is one of the first recipes within the FAIRplus project, and served as a pilot to develop a structured FAIRification process.
2.1. Ingredients¶
Raw Data: AMR Compounds Database
Metadata Model
Vocabularies and Terminologies
Data Format:
Excel spreadsheet
Tools and Software:
2.2. Objectives¶
The current AMR dataset is stored in a local webpage at UNICA. We make the AMR data more accessible by extracting the data into a public repository using machine readable format, as well as improvement of some FAIR parameters.
2.3. Step by Step Process¶
2.3.1. Dataset description¶
The AMR database consists of several nested static HTML pages. The information is well structured, results are mainly quantitative numeric data, and for all compounds a complete set of data is available. Thus, it should be easily linkable to other public sources (e.g. PubChem) and a machine-readable data set should be easily created.
To get a good understanding of the AMR dataset, the AMR metadata shall be extracted. The AMR metadata includes three types of metadata: structural metadata, administrative metadata, and descriptive metadata. The structural metadata describes the structure of the dataset, for examples, column names and/or IDs. Administrative metadata contains the author, organization, and other provenance information. The descriptive metadata includes the procedure, usually protocols, in generating the experimental results. The descriptive metadata is always stored in a free-text format without data structure.
Fig. 2.28 is an example of the simplified schematic workflow of FAIRification, which includes the extraction, the transformation, the annotation, the licensing and the identifier assigning process. Due to time constraint, we focussed on the extraction and annotation of structural metadata. The administrative and the descriptive metadata will be added in the future.
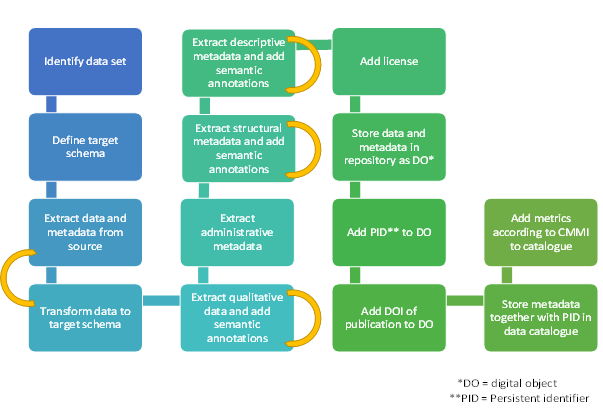
Fig. 2.28 Schematic workflow of the general FAIRification pipeline. Some steps need repetitions (yellow arrows).¶
2.3.2. Data extraction¶
Data are extracted using a KNIME workflow provided here, with which we can visualize the data extraction steps, handle complex data extraction workflows and be easily reproduced.
Fig. 2.29 is a screenshot of the ND4BB website, which is structured into a central part (the blue section) with data and two side columns with additional information. Here, we focus on data extraction from the central part. The central part of the home page consists of a single table with compound class names as table data configured as HTML heading level 3 (<h3>, shown in the red box in Fig. 2.30) and compounds as an unordered list (<ul>, shown in the yellow box in Fig. 2.30).
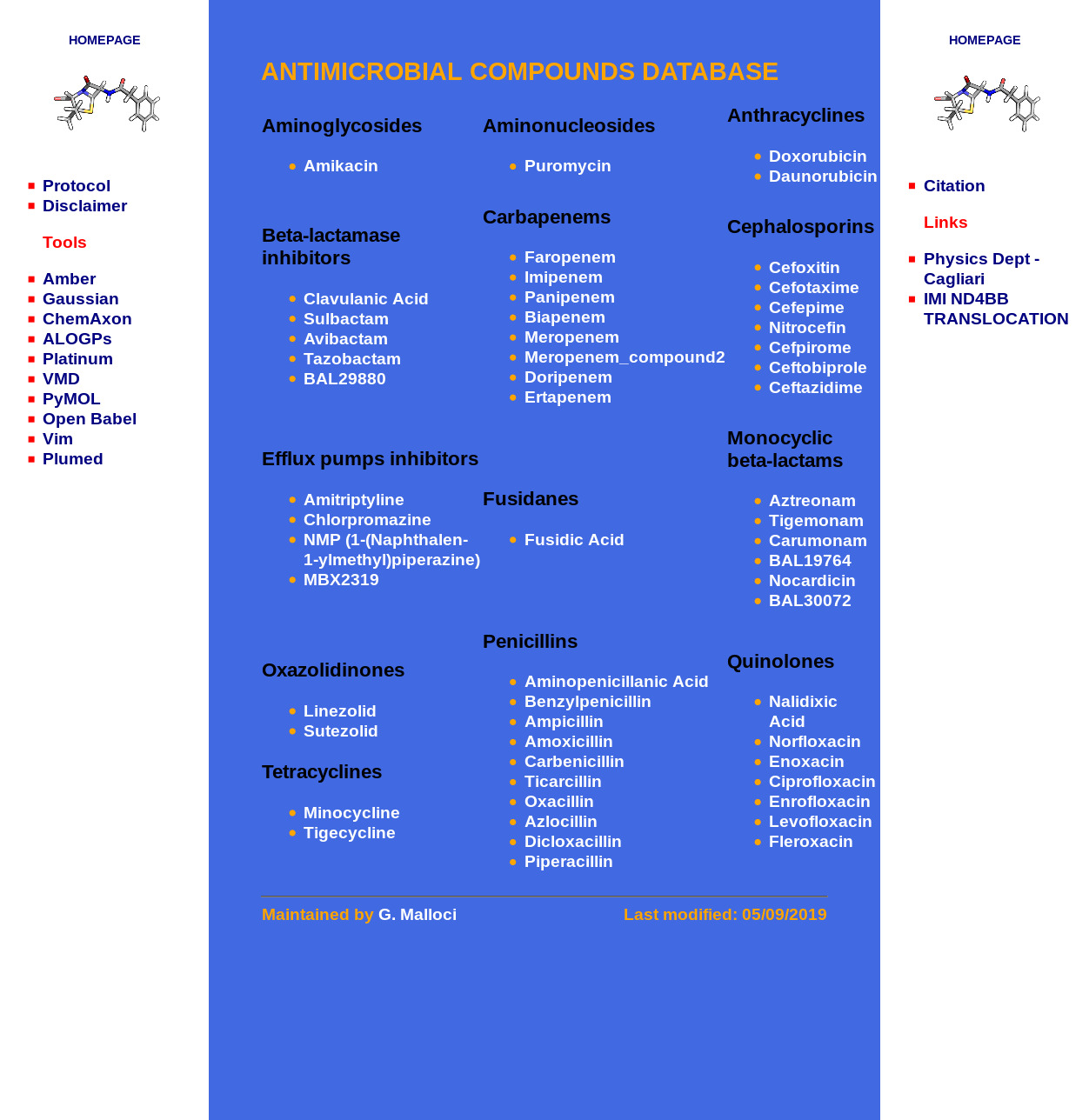
Fig. 2.29 Snapshot of AMR compound database home page. The blue area listed all compound data to be extracted.¶
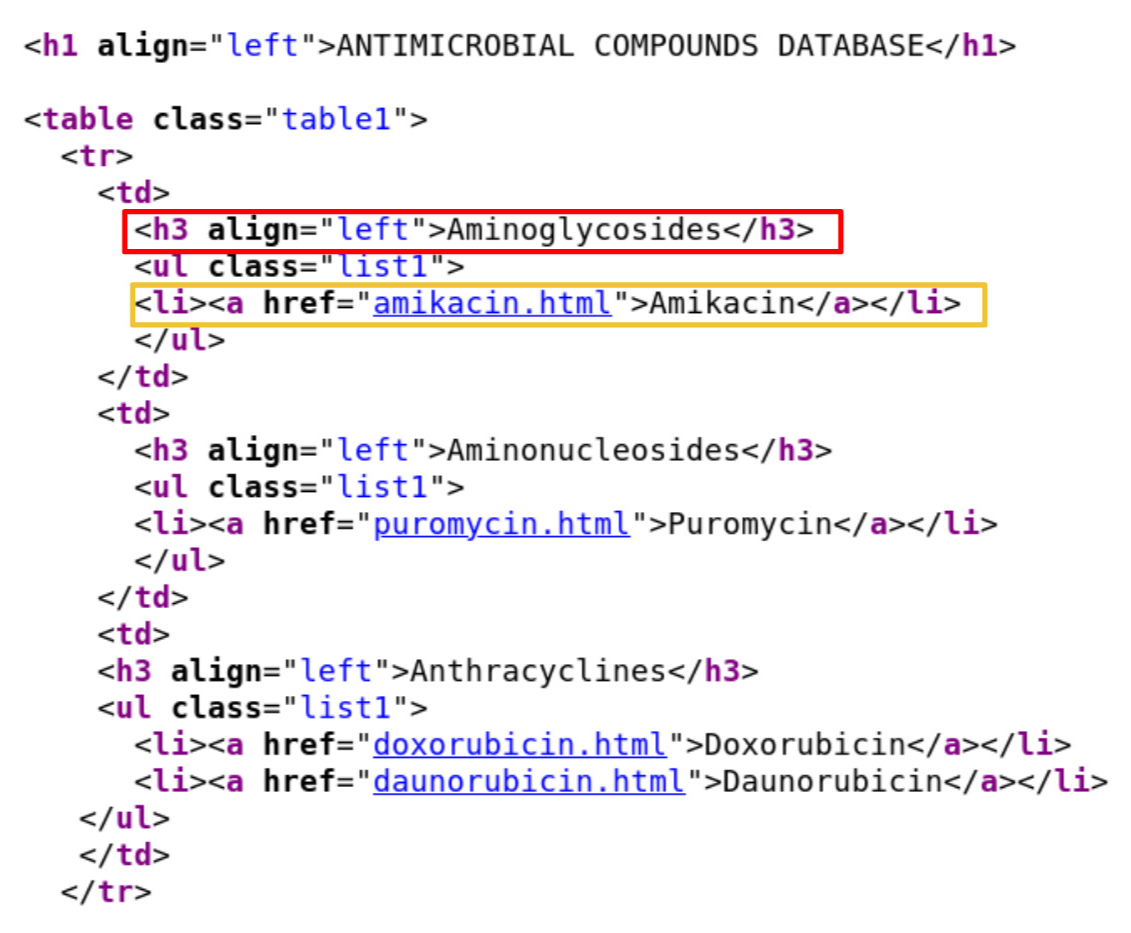
Fig. 2.30 Snapshot of the AMR compound database home page source code. The red box shows the compound class header. The yellow box lists one compound.¶
We first identified all websites that contain the project data. The homepage (Fig. 2.29) describes the compound name, the compound class and links to the compound subpage. Such information was generated using the Xpath nodes in the workflow in Fig. 2.31.
Data structure discrepancy was found in the extraction. In the compound class extraction, unlike the usual compound class structure, which is listed as a table and separated by HTML <td>…</td>, chemical “Oxazolidinones” and “Tetracyclines” use different data structure. Therefore the extracted XML document was updated before applying further nodes to the XML document. In the subpage link extraction, compound Amikacin and ampicillin have multiple subpages for differently charged molecules.
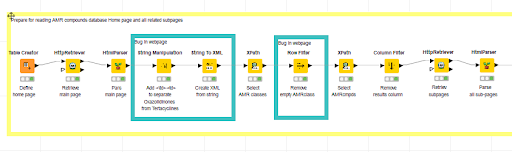
Fig. 2.31 Workflow to extract antimicrobial classes and compounds with their corresponding subpages.¶
Links to all content in the sub-page are also extracted. Fig. 2.32 is an example of the subpage of one compound, which consists of table section with the compound name, a 2D and 3D image of the compound structures, two tables with links to related files and properties and one table with links to external sources. External links were excluded from current data extraction.
The complete workflow to extract the data from the compound/charge webpage is depicted in Fig. 2.33.
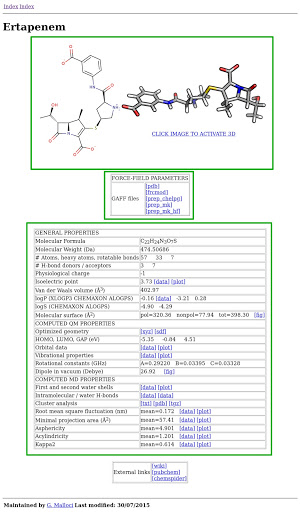
Fig. 2.32 Example of one ND4BB raw data. Marked in green boxes are a table section with the compound name, a 2D and 3D image of the compound structures, two tables with links to related files and properties and one table with links to external sources.¶
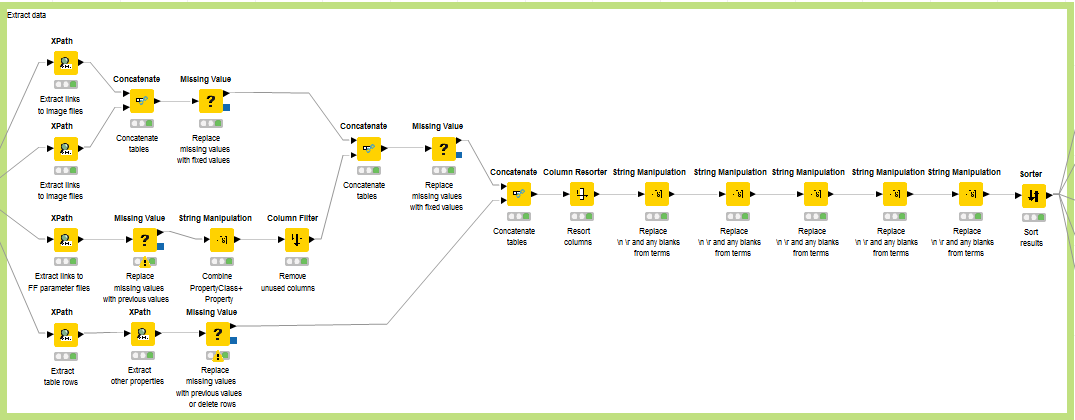
Fig. 2.33 Workflow to extract the data from compound/charge webpage.¶
2.3.3. Data transformation¶
The data were extracted following the following schema to facilitate future data annotation: “PropertyGroup - Property - Value” where PropertyGroup is the heading of the table, Property is the type of property and Value is the corresponding value of the property which will be not part of the annotation process. If the property is an image, then the “PropertyGroup” is image, “Property” is “2D/3D image”. (See the red box in Fig. 2.34. For each property, the corresponding values in a controlled vocabulary list are collected into a spreadsheet. Missing values were fixed in this step as well.
One limitation of this schema is that Excel does not explicitly describe the relations between the entities (e.g. Property Group and Property). Therefore predicates between concepts cannot be expressed (e.g. Property hasA PropertyGroup).
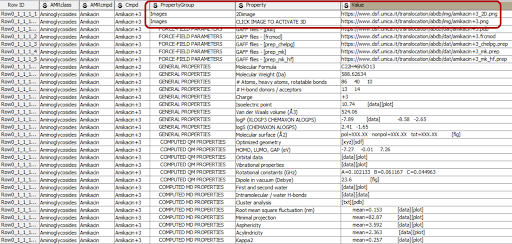
Fig. 2.34 Example data set for +3 charged Amikacin.¶
2.3.4. Extraction and annotation of structural metadata¶
To prepare for the ontology annotation, we first generated lists of different types of attributes, which include “AMRclass”, “AMR compound”, “PropertyGroup”, etc. In each spreadsheet, the values are listed as separate rows for ontology annotation.
The strings went through additional parsing to improve mapping confidence. Duplicated or missing attributes were removed. Stemming and lemmatization were implemented to map the keyword to its root form to avoid mismatch due to spelling or form variations.
All the strings were sent through ZOOMA/NCBO API to search for ontology annotation. The ontology annotation results are listed here (result Excel file for querying ZOOMA, result Excel file for querying NCBO). The ontology annotations were ranked and selected based on its confidence. For strings that didn’t find proper ontology mapping, the original values were kept. The ontology annotation preparation workflow is here.
Both ZOOMA and NCBO ontology recommenders returned the nearly same number of annotated terms, also the number searched ontologies for the NCBO Recommender (313) was much higher than the number of searched ontologies for the ZOOMA (11) service. For only a few cases did the NCBO Recommender show results (e.g. BAL29880 and MBX2319) where ZOOMA did not find a corresponding ontology.
One important difference between these two ontology mappers is that they process special characters (e.g. -_#) and spaces differently. For example, in NCBO, among “ ‘beta-lactamase inhibitors’, ‘beta lactamase inhibitors’ and ‘betalactamase inhibitors’ only the ontology annotation of the first item was found. While ZOOMA returned ontology annotation results for all three descriptions. Another example would be Aminonucleosides, Aminonucleoside, Amino nucleoside. While NCBO Recommender found no result, ZOOMA found at least a result for the terms ‘Aminonucleoside’, ‘Amino nucleoside’. This proves the necessity of running stemming or lemmatizing prior to ontology mapping service.
Provenance metadata about the ontology annotation pipeline implementation are stored here in the same file.
2.3.5. Evaluation of the ontology annotation¶
Both generated files ‘ExtractedMetadata_20190124_ZOOMA_0329.xlsx’ and ‘ExtractedMetadata_20190124_NCBOREC_0347.xlsx’ show nearly same number of annotated terms, also the number searched ontologies for the NCBO Recommender (313) was much higher than the number of searched ontologies for the ZOOMA (11) service. For only few cases the NCBO Recommender showed results (e.g. BAL29880 and MBX2319) were ZOOMA did not find a corresponding ontology.
The proposed workflow is insufficient to extract adequate and consistent semantic annotations for the structural metadata. In addition the retrieved links do not reflect the used version of the ontology.
2.4. FAIR assessment¶
We conducted an assessment of the FAIRness of the dataset, with the results stored here. Although there are a few indicators that are not applicable to the ND4BB dataset because of data type limitations, and some indicators are too ambiguous to provide a objective assessment. We got different data curators evaluating the FAIRness separately and compared and discussed the conflicting assessment. In general, the FAIRness score against RDA FAIR indicator is 36%, of which the mandatory indicator score is 47% and the recommended indicator score is 32%.
2.5. Possible next steps¶
Extract administrative metadata, provenance information, e.g. owner, date of creation
Add a license to data set
Store data (=experimental results) together with administrative, structural, and descriptive metadata in a public repository
Add PID to data set (=digital object)
Add metadata together with PID to a public catalog
Add metrics according to CMMI and add to the public catalog
Add checksums for all files for QC and integrity checks
Expand the ontology annotation to all terms
2.6. Conclusion¶
The AMR dataset was provided as a first example as it was immediately available. A generic FAIRification workflow was also provided. We reviewed the workflow and derived general principles for the cookbook. However (as for the principles we learnt) the lack of a context for the data, and the lack of goals for the FAIRification process made the actual action of FAIRification not valuable.
As a result of our work on the AMR dataset, we identified useful general principles, including the need for license, availability of the data, the importance of context (e.g.: what ontologies to map to) and other details included in our report.
We also identified key FAIRification steps in the proposed process, some of which are non-obvious (e.g.: capture modifications done to ingest data). On this basis we started to sketch a generic workflow.
Overall this dataset has been very useful to start our overall process and team activities.
2.7. References¶
References
2.7.1. What to read next?¶
FAIRsharing records appearing in this recipe:
2.8. Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
Manfred Kohler |
Fraunhofer Institute |
Writing - Original Draft |