

Main Content¶
Data management, especially the management of personal information, is a sensitive activity which requires a number of specific considerations and, depending on the part of the world where the operations are taking place, specific legal frameworks will apply. Since its adoption in 2018, the European Union General Data Protection Regulation (GDPR), by inscribing privacy of information as fundamental right, established a standard for the domain by providing boundaries to what had been, for a long time, an unregulated space.
What does the GDPR regulation imply for the research practice and why does it matter for healthcare research?
The regulation means that, prior to conducting any data processing involving human personal information, a Data Protection Impact Assessment (DPIA) needs to be carried out.
In the event that the intended data processing includes data provided by a third party, then the use of this data is dependent on the data access and data use conditions, established by a DPIA formulated by that third party.
Failure to generate a GDPR-compliant DPIA or adhere to condition(s) imposed by a third party may result in legal actions for breaching the regulation.
In the following sections, we will examine the key steps to consider when generating a DPIA and how to code such information in machine-readable form, utilizing the ‘Data Privacy Vocabulary’ (DPV) 2 and its extensions.
Survey the data types of the project¶
During the survey of the data types, if it becomes clear that personal, patient centric information will be processed within the EU, then the GDPR regulation applies (i.e. a multi-centric, international clinical trial recruiting patients in the EU and/or outside the EU the data of which will be processed in the EU falls under GDPR).
In the context of scientific research, the purpose of the research can be explicitly determined as a justification for the data collection activity.
Identifying the key entities:¶
Under GDPR rules, the first requirement is to nominate and identify physical or legal entities that will perform key functions. These functions are:
Data Protection Officer: An entity within or authorised by an organisation to monitor internal compliance, inform and advise on data protection obligations and act as a contact point for data subjects and the supervisory authority.
Data Controller: The individual or organisation that decides (or controls) the purpose(s) of processing personal data.
Data Processor: A ‘processor’ means a natural or legal person, public authority, agency or other body which processes personal data on behalf of the controller.
Then, it is necessary to declare all the purposes, anticipated uses and actions on the collected data, so these can be clearly listed and documented.
For each of these actions, a justification needs to be provided, explaining the reasons why information is collected and how it contributes to answering the research questions.
The results of this survey should also be included in the informed consent, which will be reviewed and signed by the participants (Data Subjects) in the research project.
The availability of a new semantic resource, developed as a W3C specification, provides the necessary vocabulary to structure information which was until now only available in natural text and legal documents. The figure below shows an excerpt of the Data Privacy Vocabulary in the Protégé ontology editing tool.
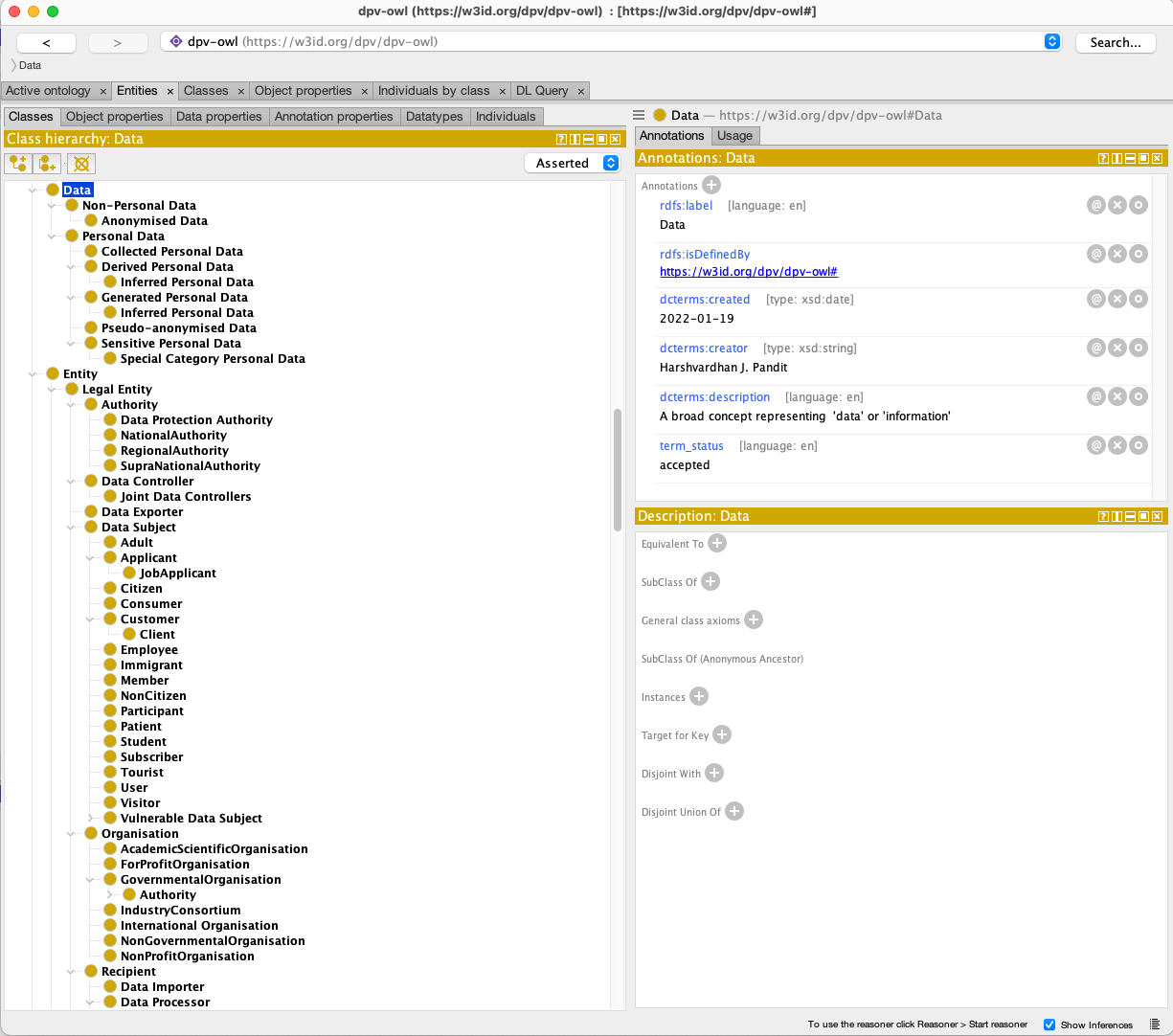
Fig. 18 A snippet of the Data Privacy Vocabulary as seen in Protégé ontology editor¶
In the following RDF fragment, we show how to express the goal of the data collection of an exemplar study.
@prefix dpv: <https://w3id.org/dpv#> .
@prefix dpv-nace: <https://w3id.org/dpv-nace#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ex: <http://example.org/> .
ex:research_purpose a dpv:Purpose ;
rdfs:Label "Identifying therapeutic targets among solute carrier genes to cure rare diseases" ;
dpv:has_sector dpv-nace:M72 .
Note
This snippet also makes use of the NACE extension, the scope of which is The Statistical Classification of Economic
Activities in the European Community. NACE stands for “Nomenclature statistique des Activités économiques dans la Communauté Européenne”)
The Natural Persons¶
These types are meant to formally identify physical persons.
@prefix dpv: <https://w3id.org/dpv#> .
@prefix dpv-nace: <https://w3id.org/dpv-nace#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix ex: <http://example.org/> .
ex:Person1 rdf:type foaf:Person, dpv:NaturalPerson .
The legal entities¶
These types are meant to assign a function (or a role or a state) to a physical entity, as declared following the pattern described in the previous section.
@prefix dpv: <https://w3id.org/dpv#> .
@prefix dpv-nace: <https://w3id.org/dpv-nace#> .
@prefix iso: <https://www.iso.org/country-code> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ex: <http://example.org/> .
ex:Acme rdf:type dpv:LegalEntity ;
dpv:hasName "Acme"@en ;
dpv:hasAddress "Dublin, Ireland"@en ;
dpv:hasContact "acme@example.com" ;
dpv:hasRepresentative ex:AcmeDPO, # internal DPO
ex:AcmeEUOrg ; # EU Representative
dpv:hasLocation iso:IE . # if an ISO vocabulary for country-codes is used
the functions and roles:¶
Here, we explicitly express in machine-readable form that an Organization acts as a Data Controller.
@prefix dpv: <https://w3id.org/dpv#> .
@prefix dpv-nace: <https://w3id.org/dpv-nace#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ex: <http://example.org/> .
ex:Acme rdf:type dpv:DataController .
ex:AcmeMarketing rdf:type dpv:PersonalDataHandling ;
dpv:hasDataController ex:Acme ;
dpv:hasPersonalDataCategory dpv:EmailAddress ;
dpv:hasProcessing dpv:Collect, dpv:Use ;
dpv:hasPurpose dpv:ServiceProvision .
Here, we explicitly express in machine-readable form that an Organization acts as a DataProtectionOfficer.
@prefix dpv: <https://w3id.org/dpv#> .
@prefix dpv-nace: <https://w3id.org/dpv-nace#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix ex: <http://example.org/> .
ex:Person1 rdf:type foaf:Person, dpv:NaturalPerson, dpv:Representative, dpv:DataProtectionOfficer ;
dpv:hasEntity ex:Acme .
ex:AcmeEUOrg rdf:type dpv:LegalEntity, dpv:Organization, dpv:DataController;
dpv:hasEntity ex:Acme ;
dpv:hasLocation "EU"@en .
Identifying the risks to privacy and define risk mitigation and security measures¶
With the previous steps performed, the next step consists in understanding the risks to privacy associated with the data collection and processing scenarios defined by the research program.
For each of these identified risks, a mitigation plan should be established.
A risk is defined as “a risk or possibility or uncertainty of negative effects, impacts, or consequences”.
Management of risks associated with data management has two major components. Used in combination, they ensure a strong culture of cyber-security and data security is established and, possibly more importantly, maintained.
The first arm focuses on training and ensuring personnel in charge of the data receives the proper education.
The second arm is obviously the techniques themselves and their implementations.
When dealing with human centric sensitive information, the main privacy concerns for data managers are:
unauthorized access to the data
patient re-identification
which can be represented by the following RDF statements:
@prefix dpv: <https://w3id.org/dpv#> .
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ex: <http://example.org/> .
ex:DataStore rdf:type dpv:Technology ;
dpv:hasRisk ex:UnAuthorisedAccess .
# unauthorized access risks
ex:UnAuthorisedAccess rdf:type dpv:Risk .
# patient re-identification risk
ex:ReIdentification rdf:type dpv:Risk .
Both cases are very serious security and privacy issues which demand robust policies to be in place. These situations can be de-risked by implementing different types of solutions. In the following paragraphs, we show how ‘data anonymization’ and ‘data encryption’ can be explicitly declared as measures to mitigate patient re-identification or information retrieval in case of unauthorized access.
Organisational measures:¶
@prefix dpv: <https://w3id.org/dpv#> .
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ex: <http://example.org/> .
# 1: directly associating staff training with credentials used
ex:StaffCredentialsTraining rdf:type dpv:OrganistionalMeasure ;
skos:broaderTransitive dpv:StaffTraining .
ex:RBACCredential dpv:hasOrganisationalMeasure ex:StaffCredentialTraining .
# 2: security policy containing staff training and access control
ex:SecurityPolicy rdf:type dpv:OrganisationalMeasure ;
skos:broaderTransitive dpv:Policy ;
dpv:hasOrganisationalMeasure dpv:StaffTraining ;
dpv:hasTechnicalMeasure dpv:AccessControlMethod .
# 3: indicating staff training contains access control methods
ex:StaffCredentialsTraining rdf:type dpv:OrganistionalMeasure ;
skos:broaderTransitive dpv:StaffTraining ;
dpv:hasTechnicalMeasure ex:RBACCredential .
Technical measures:¶
@prefix dpv: <https://w3id.org/dpv#> .
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ex: <http://example.org/> .
ex:RSAEncryption rdf:type dpv:TechnicalMeasure ;
skos:broaderTransitive dpv:Encryption ;
skos:scopeNote "Key size: 2048, Custom Implementation"@en .
ex:RBACCredential rdf:type dpv:TechnicalMeasure ;
skos:broaderTransitive dpv:AccessControlMethod .
@prefix dpv: <https://w3id.org/dpv#> .
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ex: <http://example.org/> .
ex:RSAEncryption rdf:type dpv:Anonymization ;
skos:broaderTransitive dpv:Encryption ;
skos:scopeNote "Key size: 2048, Custom Implementation"@en .
ex:RBACCredential rdf:type dpv:TechnicalMeasure ;
skos:broaderTransitive dpv:AccessControlMethod .
Note
RiskOnto is an ontology of risk, extending the Prov-Model developed to provide semantic support to explicitly describe risk. RiskOnto expresses ‘risk related concepts based on ISO 31000 series’ as a vocabulary and an ontology . For more information, see the dedicated github repository: https://github.com/coolharsh55/riskonto 1
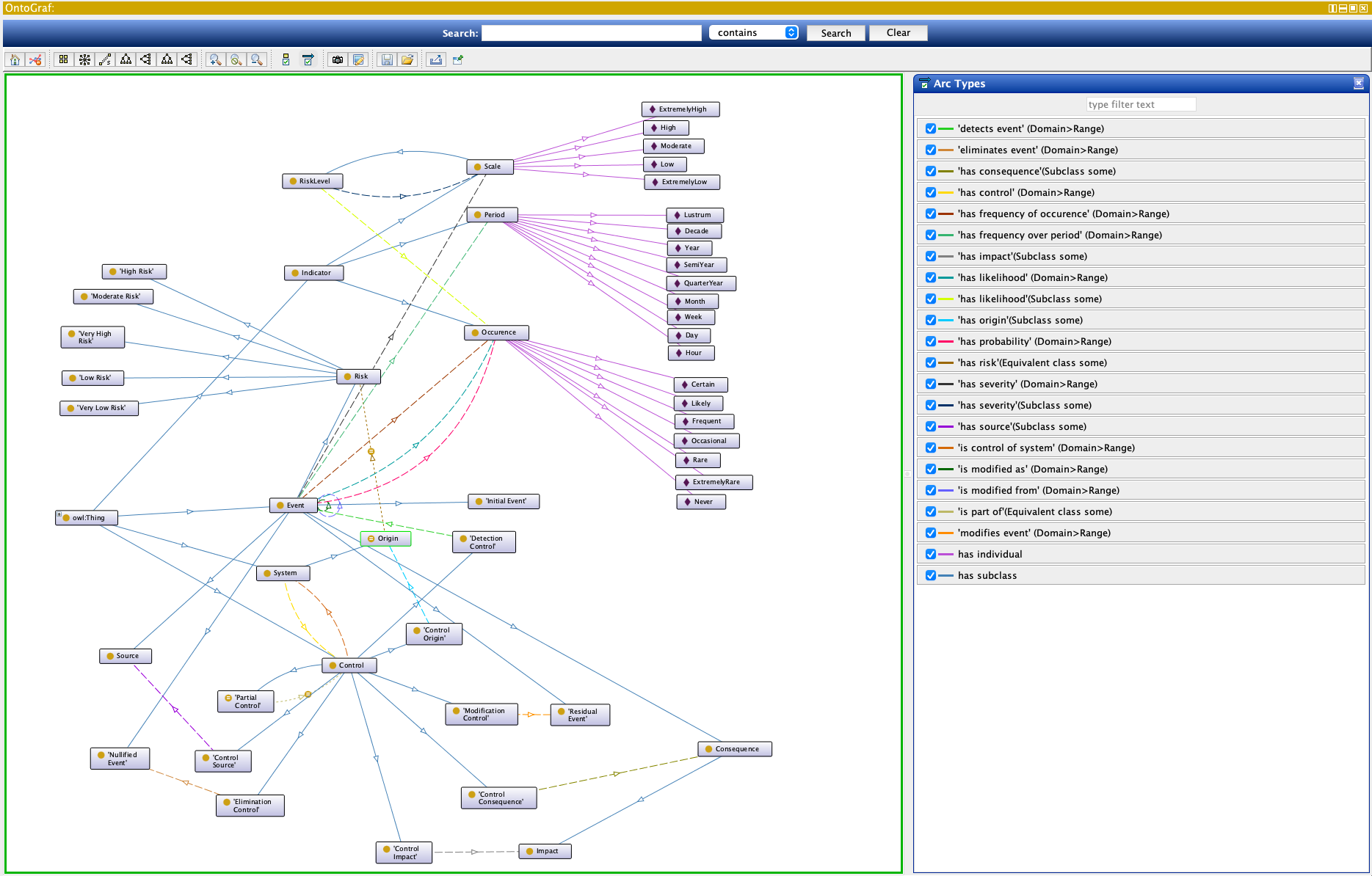
Fig. 19 riskonto viewed with Ontograf in Protégé 5.5¶
Now, revisiting the declaration of risks, we can add a statement to indicate what risk mitigation methods have been
devised and use the dpv:isMitigatedByMeasure relation to relate the risk to the procedures set in place.
@prefix dpv: <https://w3id.org/dpv#> .
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ex: <http://example.org/> .
ex:DataStore rdf:type dpv:Technology ;
dpv:hasRisk ex:UnAuthorisedAccess .
# 2: risk registry denoting risks and mitigations
ex:UnAuthorisedAccess rdf:type dpv:Risk ;
dpv:isMitigatedByMeasure ex:RBACCredential ;
dpv:isMitigatedByMeasure ex:RSAEncryption .
# patient re-identification risk and
ex:ReIdentification rdf:type dpv:Risk ;
dpv:isMitigatedByPatient ex:RSAEncryption .
Data Access Requests, Data Access Agreements and DPIA:¶
Data access requests need to be considered when devising a data protection impact assessment as part of the data governance.
Data access requests are common situations whereby researchers may seek access to research data from another group, within the same jurisdiction or outside the jurisdiction.
Data access requests need to be appraised and evaluated by specific structures, the Data Access Committees (DAC), which establish policy documents detailing the conditions of access and terms of data reuse.
The DAC will evaluate the requests and actions on the data planned by the requester against the data permitted use associated to the dataset. Depending on this assessment, the DAC will decide whether or not to grant the request.
For more information about ‘data permitted uses’, see this dedicated recipe FCB035:
In the context of data access requests, a DAC needs to appraise risks such as:
Use for un-consented research
Data transfer to a different jurisdiction: would the data be protected to the same level once outside EU?
Nature of transfer tools, which fall into 3 possible categories:
Standard Contractual Clauses (SCC): 18 statements which can be used to assemble a
boiler plateagreement to transfer data outside EU rule of law but in ways which conform to the EU GDPR.Binding Corporate Rules (BRC): These are legally binding rules to transfer data within the different branches of a Company, which may operate in different countries. BRCs need to guarantee at minima the same level of protection as the Standard Contractual Clauses.
Code of Conducts (CoC) Code of Conducts represent data protection policies developed for a particular type of data and/or for a particular professionals. For example, Cloud Security Alliance Code of Conduct
Data leak or data breach
Individual re-identification
A specific data protection impact assessment is needed for each request and this can be a time-consuming operation.
This is where the availability of machine-actionable representations of legal documents such as DPIA, data use agreements, and data access requests can yield great benefits. By enabling the creation of readily exploitable documents, it could help the development of automated assessment tool, which would expedite decisions regarding data access while potentially reducing the risks associated with the use of sensitive information. Privacy preserving use of data is of paramount importance to retain the public confidence in the scientific practice and the safe-keeping of information.
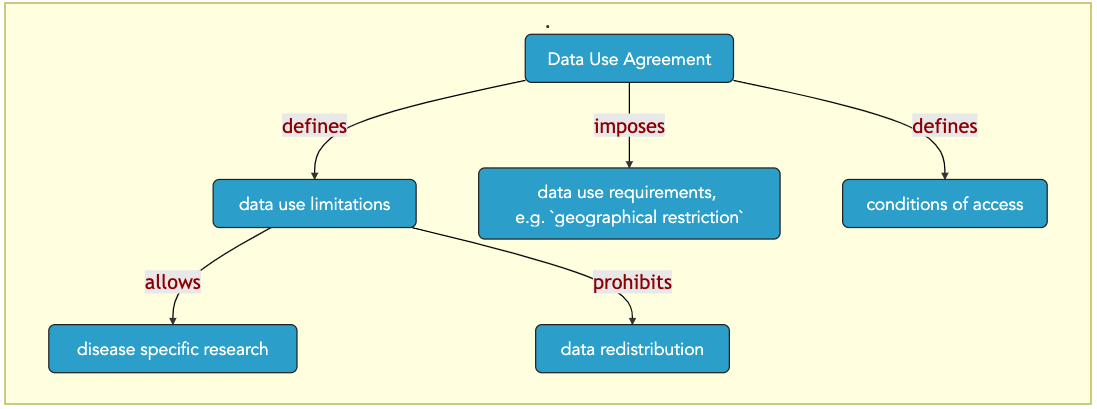
Fig. 20 data-use-agreement¶